第一章 Overview
AI 是什么?
大家应该之前或多或少听过很多了. 就算没专门查过和看过, 也大概有"人工智能就是让电脑像人一样"的模糊感觉. 毕竟这个名词非常"恰如其名", 就是"人类制造的智能".
感性地说, 人工智能是研究和制造能够模仿, 扩展人类智能的系统.
注意, 当我们在考察系统的智能时, 我们是否在意它的结构?
假如说, 我们有一个程序, 它很简单, 它会把输入句子中的"吗?"替换成"!", 把"你"替换成空, 把"我"替换成"你". 你会认为这个程序有智能吗?
人: 在吗?
程序: 在!
人: 你好吗?
程序: 好!
人: 我做得好吗?
程序: 你做得好!我们很明显不认为它有智能. 但是或许在某些特定情况下, 真的可以骗到人一小下. 这还仅仅只有 3 条规则. 如果我们有非常多的规则, 上万条乃至上亿条, 你还能确定你不会在一无所知的情况下被程序骗到吗?
但是你会认为这种基于规则的结构拥有智能吗? 我想一些人会认为"这种结构怎么能说是智能呢?" 但应该还是有一些人觉得"难说!", 因为规则够多够复杂, 说不定就有智能了, 毕竟我们大脑, 单拿出来一个神经元也挺简单的.
这个问题确实很难说. 不过如果我们认为系统的结构本身影响其是否是智能, 会影响我们理论的发展. 因为我们必须考虑"什么样的结构是智能"这个超难的问题. 相比之下, 只考虑"系统的表现像不像智能", 就显得简单多了.
所以, 至少在大多数讨论情景下, 我们都认为"是否具有智能"这件事, 要从系统的表现来看, 而与系统的内部结构无关.
在这个前提下, 我们引入机器学习视角下的智能:
定义输入空间
如果这个性能评价函数被我们设计成了"我们认为符合智能的样子", 通过机器学习方法, 就可以去寻找这个最好的映射. 例如, 我们的输入空间是全世界所有的图片组成的集合, 我们的输出空间是这张图片里的是猫还是狗, 我们的性能评价函数就是映射对所有图片分类结果的正确数量, 那么我们寻找最大正确数的映射的过程, 就是在寻找我们认为的"可以分类猫和狗的智能".
在大多数问题中, 由于输入和输出空间很大, 映射空间也很大, 我们只能采样, 获取样本, 然后将映射参数化, 使用数理统计方法估计映射的参数.
AI 的发展历程
这里省略。大家可以查看这篇文章来详细学习。
深度神经网络
神经元
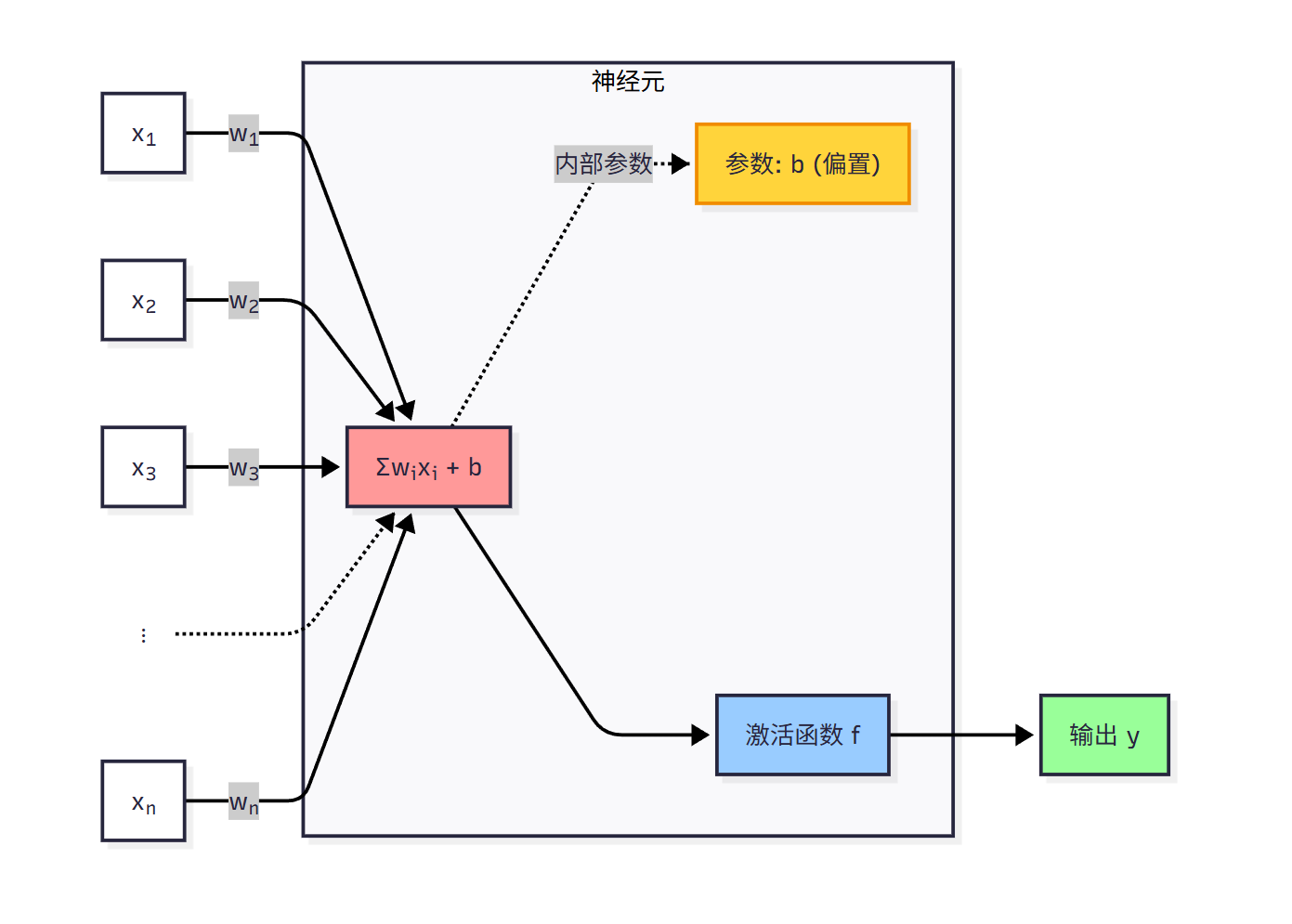
深度神经网络的基本组成单位是神经元. 传统意义的神经元有多个输入和一个输出.
一个神经元有多少个输入, 就有多少个权重. 权重是个标量值, 用于表示联系的紧密程度.
假如说一个神经元有
实际上就是加权求和.
我们会发现, 神经元的输出, 对于任意一个输入来说都是线性的. 我们为了提高神经元的表示能力, 可以进行一个非线性映射. 这个映射我们称之为激活函数. 这里用
常见的
[施工, 介绍一下这三个函数]
这样神经元就比较完整了. 不过我们还希望神经元拥有对自己的输入进行整体平移的能力, 这就引入了偏置 bias, 我们一般用
这样的神经元一共有
线性神经网络层
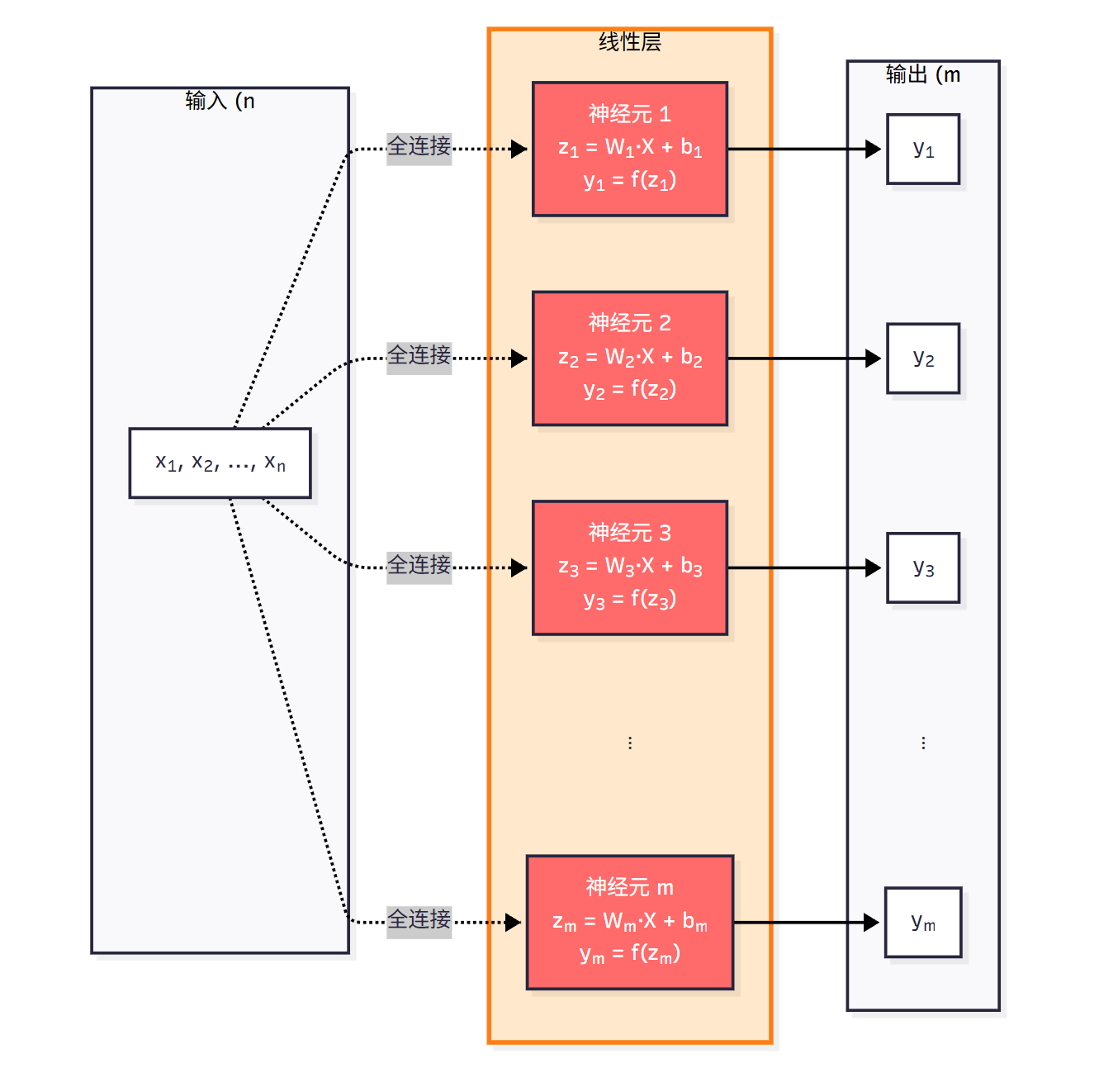
将
我们把输入组织成一个
其中, 每一行代表一个神经元的输入. 我们也把权重组织成一个
其中每一行代表一个神经元的所有权重值. 我们把偏置表示成一个
每个神经元都进行相同的计算, 因此我们可以把线性神经网络层的计算用下面的线性代数操作表示:
这里的
你可能会在别的地方看到这么写:
为什么
需要转置? 这是因为在实际实现中, 是个矩阵, 它的形状为 . 很好理解, 而 你可以暂时理解成, 为了效率, 我们需要批量处理数据, 要把很多个输入数据拼起来, 向量就被拼成了矩阵. 而且这里为了好看, 还把 的形状从 改成了 . 的形状也要改过来.
多层感知机 MLP
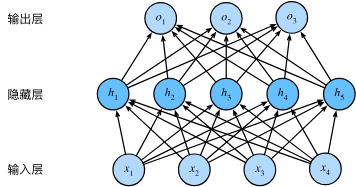
将多个线性神经网络层直接前后连接(即前一层的输出是后一层的输入), 就构成了多层感知机 MLP.
一般的 MLP 图中的第一层其实是输入层, 不算做层数里面, 只是提供输入值. MLP 的关键参数设置是每层的神经元数量. 理论上已经证明, 只要足够大, 两层的 MLP 就可以以任意要求精度拟合任意任务.
神经网络的参数优化
神经网络拥有一些(大多数情况下是大量)可学习参数. 但是网络并不是平白无故就有了一组能解决问题的好参数. 我们并不知道面对一个任务时, 神经网络到底该采用什么参数. 但是神经网络可不是
神经网络的参数寻找似乎很困难, 不过这里我们先考虑一个更加通用的场景:
假如说我们有一个带参函数
现在, 我给你一组有序对
在高中, 我们会利用残差平方和最小来直接算出这个参数. 在
- 首先, 我们需要找到一个衡量
有多好的方法. 在这里, 我们选择了残差平方和函数的值. - 然后, 参数寻找问题变成了求函数极值点的问题, 即将
看作变量, 求残差平方和函数的极小值点.
神经网络参数优化, 也使用相同方法. 我们把神经网络看作一个函数
为了让参数有个优化的依据, 我们需要数据集. 数据集是从环境中采样得到的样本集合. 一般来说会带有一定的随机性和方差. 每个样本都由两部分组成: 特征(feature)与标签(label). 特征即样本的一些属性, 标签则是对应样本的真实值. 例如, 你想要构建一个天气预测的数据集. 你统计了几百天的天气, 特征就是每天的属性(或者前一天的属性, 如果是为了预测的话), 例如温度, 湿度, 风速, 云的形状等, 标签就是每天的真实天气, 如晴天, 多云, 小雨等.
这里我们将数据集表示为
损失函数肯定是有关
梯度与梯度下降
高数里其实对梯度也有比较多的介绍了. 简单的理解可以认为梯度是导数在多维情况下的扩展. 其直观含义是函数值的增大方向. 即每个参数应当怎么变化, 才能使得该点处函数值最快速度增大.
梯度的非常不严谨讲解:
我们先引入雅可比矩阵. 一个函数有
比较好的事情是, 我们的损失函数一般来说是个标量函数, 即输出只有一个值. 因此在我们的场景下, 雅可比矩阵应该是个向量, 此时, 我们称之为梯度(而不是雅可比矩阵):
如果我们可以计算出损失函数对网络参数的梯度, 至少我们可以知道在某点, 参数往哪个方向变化, 函数值减少(相比于增大只是乘个-1 即可, 即负梯度)最快. 我们采用贪心策略, 每次都只往函数值减小最快的方向前进一小步. 随着迭代步数的增加, 我们期望我们可以走到函数的最小值位置.
下面用一个简化的例子来形象说明这个过程.
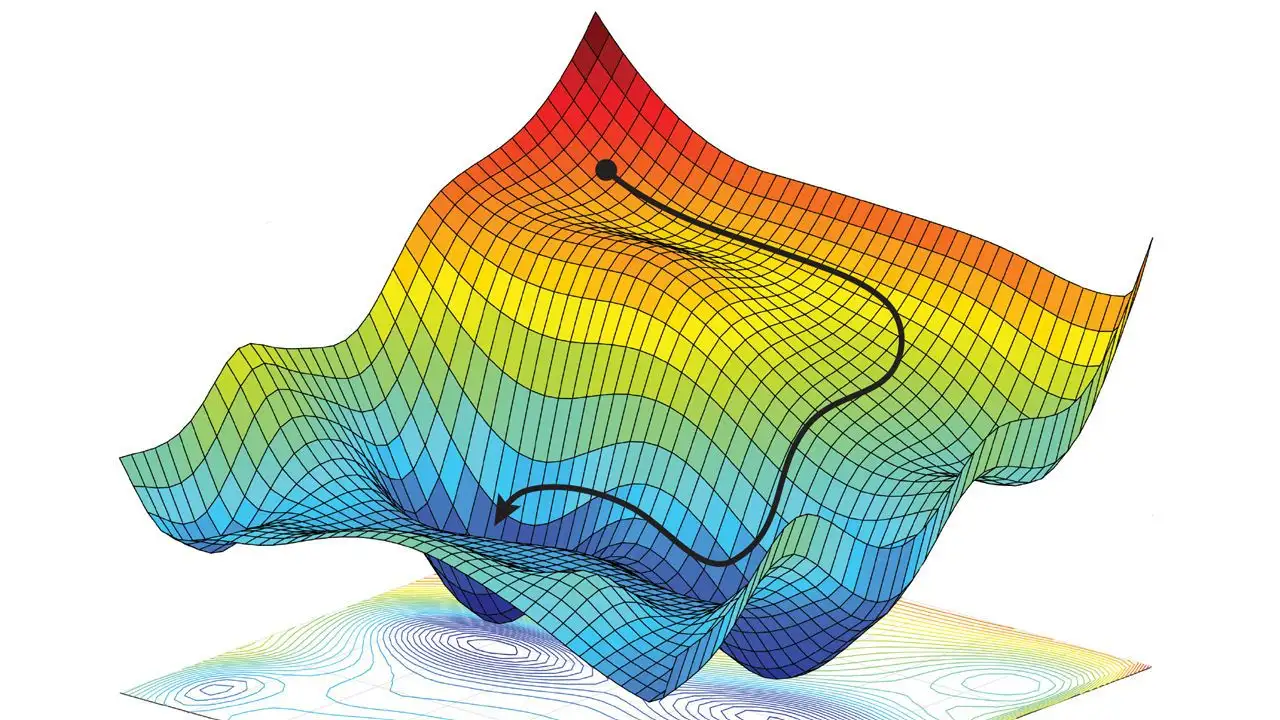
图中是一个二元函数, 从图中可以直观看出函数的形状. 我们通过梯度下降法寻找最低点的过程, 就是图中的黑色轨迹. 我们每一次都向当前位置函数下降最快的方向前进一点点, 最后形成的就是这样一条"下山"路径.
假设我们在某点处的梯度为:
则
我们如果采用梯度下降法进行神经网络参数的优化, 就需要有一种计算神经网络中每个参数梯度的办法. 其实, 神经网络每一层的计算是比较简单的, 而是神经网络每一层看作一个独立的函数, 其计算过程就是一个递归的嵌套函数:
我们对参数求梯度(求导), 可以运用链式法则. 假设我们想要求损失函数对第
这个式子简化了一些, 没有拆分到更细的微分式. 不过, 总归是有办法计算的. 我们可以就这么求出全部参数的导数, 我们就得到了梯度. 并且, 这个计算过程是一层一层的(后面的层可以复用前面计算的结果), 从后往前(由深及浅), 计算梯度并进行参数更新的过程也被称为反向传播.
因此, 我们在构建网络的过程中, 会慎重考虑组件的数学性质, 尤其是求导的便利性. 例如, sigmoid 激活函数被我们选择, 不只是因为它能将输入压缩(而且压缩后相对大小不变)到
我们在前向传播的过程中, 保留计算 sigmoid 函数的值
但是 sigmoid 函数也有自己的问题: 当
这块内容值得讲的有很多. 但是限于篇幅和课程性质, 无法详细展开. 希望大家可以自己课后查一查相关的东西.
梯度下降的问题与解决方法
大家可以看出, 梯度下降的这种下降其实是盲目的, 很容易下降到局部极小而不是全局最小. 为了防止梯度下降法优化的模型参数陷入局部极小, 我们引入了正则化方法.
正则化方法其实本质是为了预防过拟合问题. 当数据集过小(或者说是种类过于单一), 无法比较好地代表数据的真实情况时, 对于神经网络这种表示能力强的模型来说, 很容易遇到过拟合的问题. 其表现为在训练数据集上效果非常好, 但是在真实数据上却差很多. 直观理解是模型学习到了不属于总体的知识. 例如你的数据集中大部分是中国的气象数据, 其它地方的数据很少. 然而真实场景中是在全球范围内随机抽选地区进行气象预测. 中国的气象数据中肯定包含气象变化的一般规律(我们希望模型学到的), 但是也包含了中国这个特定地区的特有变化(其实我也们希望模型学到, 但是要注意区分地区), 如果数据集中大多数样本来自中国, 模型就会认为中国地区的特色气象就是全世界气象的共性. 导致从整体来看性能下降.
在神经网络训练中, 传统的正则化方法有 L1 正则化与 L2 正则化. 不过现在更多使用 Dropout 方法. Dropout 效果非常好.
这种从某个子集中学习到的成果, 运用到父集合中的过程, 我们称之为泛化.
AI 技术栈
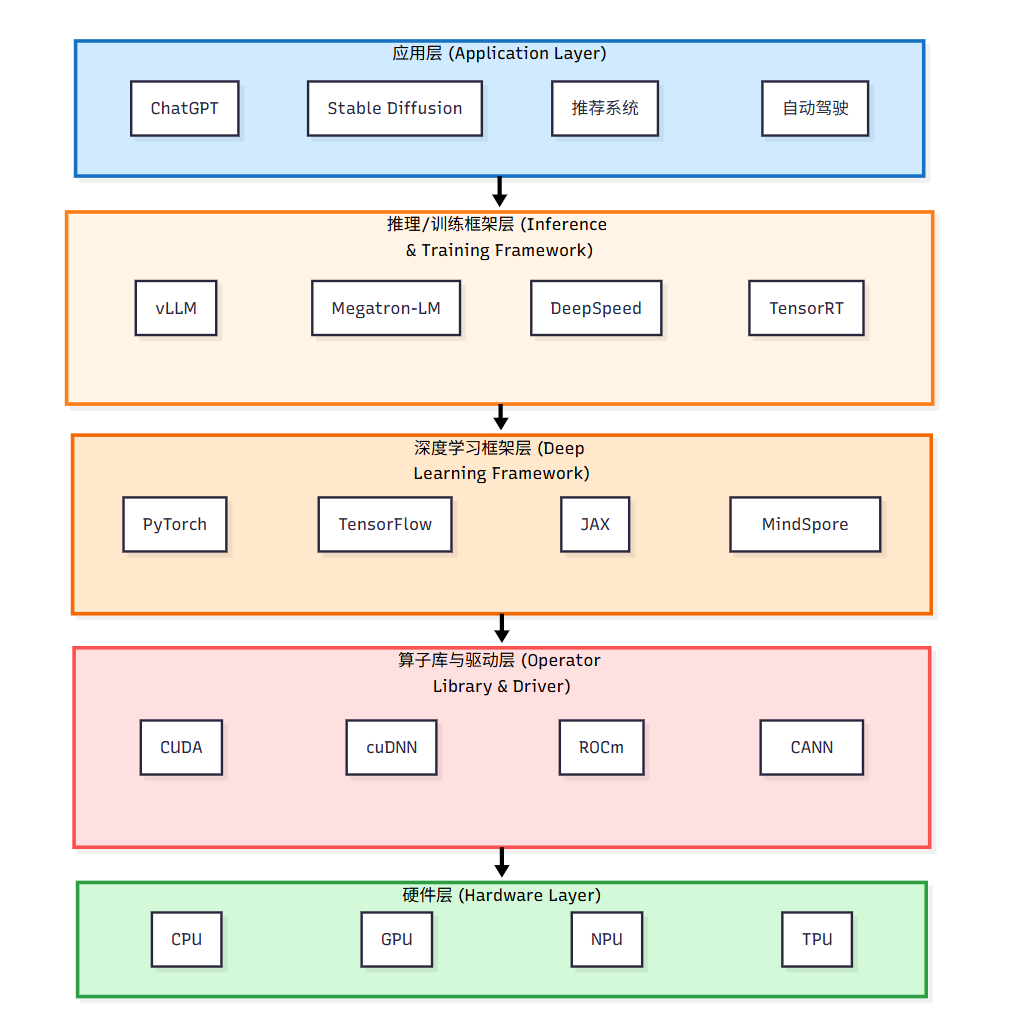
AI 应用
大家可能在很多的地方听说过 AI 的应用. 其中最让人感觉像 AI 的应用就是各种 AI 聊天应用(ChatGPT, Gemini, Claude, 千问, 豆包等). 正所谓语言是思想的载体, 通过语言, 人们第一次能直观地感受到 AI 的"思想".
AI 的应用远远不止是这类 ChatBot 以及其衍生出的服务(代码补全, agent 等). 还有图像生成, 推荐算法, 自动驾驶等. 而现代的 AI 应用往往核心是深度学习. 其参数非常巨大, 往往需要在集群上进行分布式训练, 这导致代码比较复杂. 于是有人开发出了训练/推理框架.
推理/训练框架
推理框架(常见的是 vLLM 与 TensorRT), 是为了便于模型部署而被开发出的框架. 它们往往专门为了部署场景进行了大量优化, 以达到强悍的性能.
训练框架(Megatron-LM 与 DeepSpeed), 是为了便于大规模模型训练而被开发出的框架.
深度学习框架
一般来说, 虽然推理与训练框架有大量自己的优化, 其核心依然会大量使用深度学习框架. 深度学习框架提供了自动微分功能和方便的高性能张量计算 API. 有关深度学习框架的使用与实现原理, 我们将在深度学习框架的章节进行更多介绍.
算子库与驱动
本课程基本不涉及这一层级的内容. 算子库是把一些通用操作(例如加减乘除, 矩阵乘, 求和等)的代码提前编写好, 并且进行了极致的优化. 深度学习框架一般会调用算子库中的算子来完成计算.
驱动更加底层, 其涉及更多架构知识, 是软件与硬件的交接层, 这里不作介绍.
硬件
所有的计算最终都由硬件完成. CPU 设计出来是为了应对更加广泛的场景, 而不是大量的张量计算(线性代数计算), 导致其许多为了其它情况设计的电路用处不大. 相同的面积下, 如果我们把更多的面积用于计算单元, 而不是某些情况下的加速, 就可以达到更好的性能. 这就是垂直领域硬件设计.
相比之下, GPU 比 CPU 更擅长处理线性代数运算. 线性代数中存在大量的并行性, 依赖关系一般不复杂. 因此 GPU 的控制粒度可以较粗, 控制电路可以较简单. GPU 设计初衷是计算机图像处理, 本身就是为了这种高并行, 低控制场景而设计.
直观来看, GPU 相比 CPU, 有更多的计算核心, 可以同时进行规模更大的运算, 因此其在线性代数场景下的计算能力更强. 更多介绍同学可以自己查阅资料.