第四章 深度学习框架 PyTorch
我们知道, 深度神经网络基本可以通过一些数组操作来表示. 而 NumPy 提供了高效的数组操作接口. 我们确实可以使用 numpy 编写出高性能的神经网络推理与训练的程序, 但是这依然十分复杂.
- 我们需要手动推导每个参数数组的梯度公式. 也就是说, 我们的模型只要变化了, 我们就需要重新推导, 并且重新实现. 这很麻烦.
- 我们可以利用链式法则, 只实现每层的梯度计算, 随后递归调用. 但这依然不灵活, 因为你只能使用已经定义好的层, 如果你想要实现一个新层, 除非这个新层实际上只是已有层的复合层, 否则仍然需要手动实现梯度计算.
为了使得开发更加简单和灵活, 深度学习框架被构建.
在本章开始之前
本章开始, 你大抵是需要一台配备有 Nvidia GPU 的机器. 没有英伟达 GPU 设备, 肯定会影响你学习本章内容, 因为其中的一些代码你将无法实践. 你可以让全部运算跑在 CPU 上, 这可能会很慢. 并且, 如果你选择跑在 CPU 上, 那么你最好拥有 ≥16GB 的 RAM.
深度学习框架
深度学习框架可以快速地构建深度学习模型(其实不止是深度学习模型). 你只需要实现前向传播代码, 计算机就可以自动推导它的梯度计算方法. 因此你不需要考虑如何求导你的模型.
深度学习框架还实现了大量常用的模型和组件, 例如 MSE 损失函数, 交叉熵损失函数, 卷积神经网络, Adam 优化器等.
现代深度学习框架甚至还实现了分布式相关的通信操作, 方便大规模推理或者训练.
深度学习框架对于不同硬件平台做了深层次的优化, 使得其在深度学习场景下, 往往比 NumPy 更快. 并且, 其能方便调用 Nvidia GPU 等加速硬件.
计算图自动微分技术
自动微分
深度学习框架的核心是自动微分. 这里解释一下自动微分是什么.
我们有一个表达式
当然,
from typing import Callable
def differ(f: Callable[[float], float], x: float, epsilon: float=1e-6) -> float:
return (f(x + epsilon) - f(x)) / epsilon
def f(x: float) -> float:
return x ** 2 + 2 * x
print(differ(f, 1.)) # \approx 4通过这种方法, 我们可以让计算机估算出每个变量的微分. 让计算机可以计算函数的微分, 这称之为自动微分.
但是这种方法有一定的缺陷. 当参数量很大时, 逐个计算是很慢的(其实也可以批量计算, 但那样又内存昂贵). 并且对于很深的嵌套函数, 会有大量重复的计算. 因此, 现代自动微分并不使用这种技术.
除了定义法之外, 我们还可以使用导函数法. 我们可以提前计算出函数的导函数. 例如, 我们知道
更好的是, 我们提到过, 一些函数的导函数十分简单. 例如 sigmoid 函数与 ReLU 函数. sigmoid 函数可以复用运算结果, ReLU 函数则只需要大小比较操作. 因此, 现代自动微分技术, 采用导函数法.
这样, 自动微分的关键就在于, 如何让计算机自动推导出算式的导函数.
计算图
计算图是对算式的一种建模方法, 它便于计算机处理. 计算图中有两种节点, 分别是数据和操作. 边代表输入输出, 或者说是依赖关系. 下面是一个例子.
算式
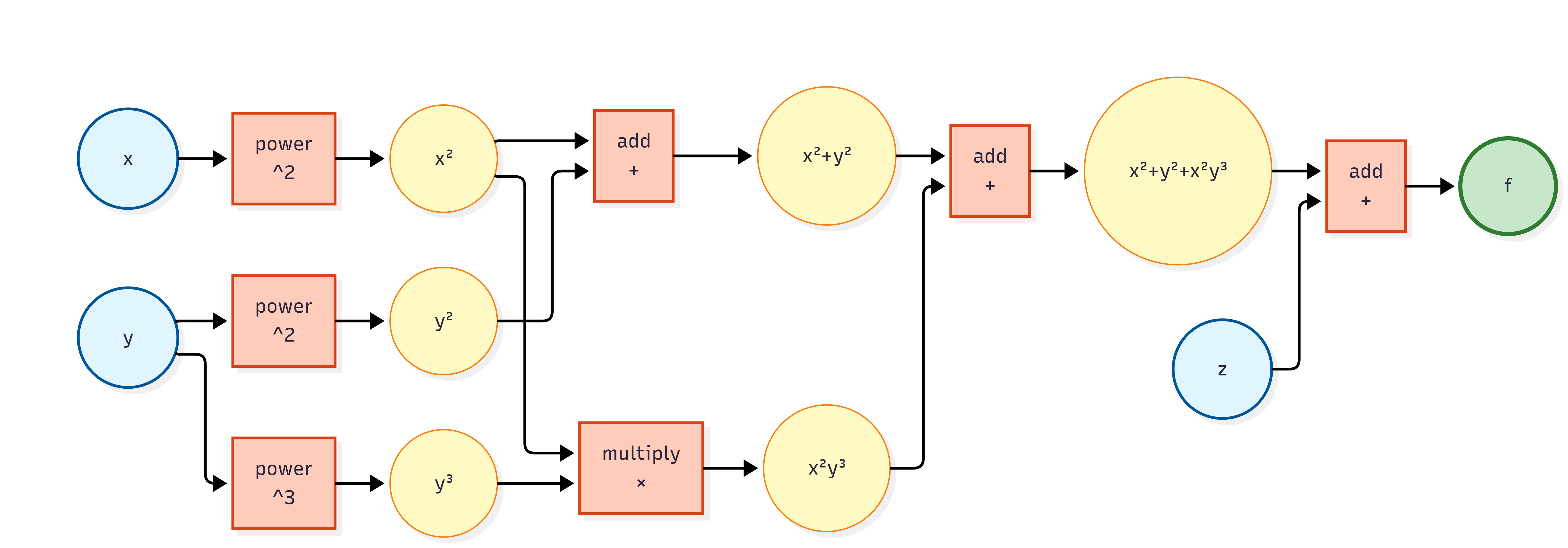
这非常好理解. 对于计算机来说, 我们使用面向对象的方式, 只需要实现 Node 类, 随后继承出 Variable 类和 Operation 类即可表示计算图. 我们可以使用指针方法来表示节点之间的依赖关系.
我们可以使用运算符重载的方法来捕捉算式构建时的依赖关系, 得知计算图的拓扑结构.
计算图与链式法则自动微分
对于复杂的算式求导是很难的, 就算是人类, 可能都很难. 但是对于单个操作求导是很简单的. 例如乘法求导, 结果就是系数; 加法求导, 结果是 1. 而算式可以看作是操作的复合. 我们可以使用复合函数求导的链式法则, 来进行求导.
对于一个由操作组成的算式来说, 对其中一个参数的导数为:
我们可以让计算机计算出每个
至于操作之间的依赖关系, 我们可以利用计算图获得. 下面用一个例子来说明.
我们就直接拿计算
我们观察计算图, 从结果向输入参数推导. 首先我们需要计算操作
我们可以发现, 加法操作对两个输入参数求导, 其实就是 1. 而我们在运行计算图时, 可以将加法操作的输入参数存储起来(而不是运算完之后抛弃). 这样就不需要存储一个很大的式子. 只需要存储数值.
现在, 我们知道了
接下来我们研究
别忘记了, 我们现在只计算了
有关
我们手工计算出了所有项. 现在我们使用链式法则合并它们
将
我们是手工计算, 一直采用符号推理. 但是计算机实现时, 实际上只保存了数值. 计算机并不是先把每个微分项推导出来, 再全部乘起来, 而是一边推导一边乘.
在实际实现的过程中, 算法会对计算图进行反向传播, 按照一定顺序遍历计算图. 不断累乘梯度值, 当遍历完成时, 也就求出了每个参数的导数值.
PyTorch 语法入门
PyTorch 是目前最常用的深度学习框架. torch 中的基本类型是 torch.Tensor, 与 NumPy 中的 numpy.ndarray 对标. 相关语法与 ndarray 几乎相同.
Tensor 张量
PyTorch 中的张量运用方式与 NumPy 中的 ndarray 数组大量雷同(为了方便迁移). torch 中的张量使用 torch.tensor 定义:
import torch
tsr = torch.tensor([1, 2, 3], dtype=torch.float16)
print(tsr)tensor 可以通过 device 参数指定 tensor 所在的设备.
设备: 对于很多异构计算结构的机器来说, 它不止拥有 CPU, 还有 GPU, NPU, TPU 等异构加速设备. 这时候你定义张量, 就需要指定是在哪个设备上定义的. 因为, 往往来说, 不同设备之间不会共用存储器. 并且, 你需要指明一个操作是在哪个设备上完成的. 例如, 你要如何指定一个矩阵乘法操作在编号为 0 的 GPU 上执行? torch 的方法是, 执行操作前, 判断输入张量属于哪个设备, 你应该让所有输入张量属于同一个设备. 当所有输入张量都属于同一个设备, 那么这个操作肯定就是在这个设备上执行的.
import torch
tsr = torch.tensor([1, 2, 3], dtype=torch.float16)
tsr_cuda0 = torch.tensor([1, 2, 3], dtype=torch.float16, device='cuda')
tsr_cuda1 = torch.tensor([1, 2, 3], dtype=torch.float16).to('cuda')
try:
tsr + tsr_cuda0
except Exception as e:
# Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
print(e)
# tensor([2., 4., 6.], device='cuda:0', dtype=torch.float16)
print(tsr.to('cuda') + tsr_cuda1)注意, 运行示例代码需要配备 CUDA 加速硬件的设备.
nn.Module 模块
torch.nn.Module 是 PyTorch 的核心组件. 它是对模型中模块的抽象建模(模型本身也可以看作一个 Module). 类似于函数, nn.Module 有输入与输出, 并且拥有参数. 它实现了 __call__ 魔术方法, 因此可以像函数一样使用.
继承 nn.Module 后, 你不需要实现 __call__ 方法, 你需要实现 forward 方法. 例如:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self, n: int) -> None:
super().__init__() # 先执行父类的init
self.n = n
_# 你可以使用nn.Parameter来包装模型的参数_
self.weights = nn.Parameter(torch.randn(n))
_# 使用register_buffer方法来注册不需要更新的张量_
self.register_buffer('no_grad_tensor', torch.randn(n))
"""
推荐使用nn.Parameter和register_buffer来定义数据.
防止在Module嵌套关系复杂之后, torch参数推导出现问题.
"""
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.weights + self.no_grad_tensor
net = Net(128)
x = torch.randn(128)
y = net(x)
print(y, y.shape)你可以使用 parameters 方法来获取 nn.Module 中所有注册的参数(返回的是生成器形式). 如果你还需要模型的参数注册时的标识符, 你可以使用 named_parameters 方法:
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, n: int) -> None:
super().__init__()
self.w1 = nn.Parameter(torch.randn(n))
self.w2 = nn.Parameter(torch.randn(n))
self.b = nn.Parameter(torch.randn(n))
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
return x1 * self.w1 + x2 * self.w2 + self.b
model = Model(128)
print(type(model.parameters()))
for p in model.parameters():
print(p)
print(type(model.named_parameters()))
for p in model.named_parameters():
print(p)
print(p[0]) _# 使用p[0]来访问参数名_模型可以整体转移到某个 device 上. 使用 to 方法:
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, n: int) -> None:
super().__init__()
self.w1 = nn.Parameter(torch.randn(n))
self.w2 = nn.Parameter(torch.randn(n))
self.b = nn.Parameter(torch.randn(n))
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
return x1 * self.w1 + x2 * self.w2 + self.b
x = torch.randn(128, device='cuda')
y = torch.randn(128, device='cuda')
model = Model(128)
try:
model(x, y)
except Exception as e:
print(e)
model.to('cuda') # 转移到cuda加速设备上
z = model(x, y)
print(z.device, z.shape) # cuda:0 torch.Size([128])损失函数
PyTorch 中定义损失函数比较灵活. 比较推荐的方式是使用 nn 中自带的一些损失函数(其本质是 Module):
import torch
import torch.nn as nn
criterion = nn.CrossEntropyLoss() # 比较常用的交叉熵损失
logits = torch.randn(4, 128) # shape: (batch_size, features)
targets = torch.tensor([0, 99, 67, 2]) # batch中每个正确类别的索引
loss = criterion(logits, targets)
print(loss.item()) # 如果不使用item方法, 则返回的是tensor(xxx), 即tensor包装的一个数, 0维
criterian = nn.MSELoss() # MSE是均方损失
logits = torch.randn(4, 128)
targets = torch.randn(4, 128) # 均方损失函数的targets输入不是索引
loss = criterian(logits, targets)
print(loss.item())其实, 你不用 nn 自带的也是可以的. 只要是运算就行. 您乐意用一个函数包装还是不乐意, 乐意用 nn.Module 包装还是不乐意, 乐意啥都不干直接写出来还是不乐意, 都看您:
import torch
import torch.nn as nn
class CustomLoss(nn.Module): # 使用nn.Module, 最正统
def __init__(self) -> None:
super().__init__()
def forward(self, predictions: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
return torch.mean((predictions - targets) ** 2)
def custom_loss(predictions: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
# 用函数包装, 还凑合
return torch.mean((predictions - targets) ** 2)
predictions = torch.randn(32, 128)
targets = torch.randn(32, 128)
criterion = CustomLoss()
loss = criterion(predictions, targets)
print(loss.item())
loss = custom_loss(predictions, targets)
print(loss.item())
loss = torch.mean((predictions - targets) ** 2) # 直接写出来, 不卫生
print(loss.item())自动求导
torch 中根据某个值反向计算出梯度, 使用 backward 方法. 我们一般对 loss 使用 backward 方法. 但是这并不意味着其它张量不可以. loss 与其它张量也并没有什么实现上的不同.
import torch
W = torch.randn(3, 4, requires_grad=True)
b = torch.randn(4, requires_grad=True)
x = torch.randn(2, 3)
y = torch.randn(2, 4)
pred = x @ W + b
loss = torch.mean((pred - y) ** 2)
loss.backward()
print(W.grad)
print(b.grad)有关张量
requires_grad参数: 该参数用于指定张量在反向传播时是否需要计算梯度. 修改该参数有很多种方式, 最暴力的方式是直接修改:pythonimport torch x = torch.randn(4) x.requires_grad = True一般来说, 张量在创建时, 可以指定是否需要梯度, 在创建张量的函数种一般会带有一个参数requires_grad. 你可以在定义张量时指定.
pythonimport torch w_no_grad = torch.randn(2, 3) w_with_grad = torch.randn(2, 3, requires_grad=True) print(w_no_grad.requires_grad, w_with_grad.requires_grad)被 nn.Parameter 包装的张量, 一般来说它的 requires_grad 是 True(会自动设置张量的 requires_grad 为 True).
pythonimport torch import torch.nn as nn w_no_grad = torch.randn(2, 3) w_param = nn.Parameter(torch.randn(2, 3)) print(w_no_grad.requires_grad, w_param.requires_grad) # False True你可以使用
requires_grad_方法来修改单个张量, 或者一个Module的参数是否需要梯度:pythonimport torch x = torch.randn(4) x.requires_grad_(True) model = Model() model.requires_grad_(False)
Optimizer 优化器
优化器用于优化一组参数. 创建它需要输入被优化的参数. 这边使用比较朴素的 SGD 优化器举例(SGD, 随机梯度下降). 首先, 你需要计算每个参数的梯度值(一般使用 backward 方法), 随后优化器使用 step 方法进行一步优化.
下面是一个示例:
import torch
from torch.optim import SGD
iteration = 100
epoch = 10
optimizer = SGD(model.parameters(), lr=1e-3, momentum)
for _ in range(epoch):
for i in range(iteration):
x, label = data[i]
pred = model(x)
loss = loss_function(pred, label)
loss.backward()
optimizer.step()数据组织
在前面的优化器示例中,我们通过列表推导式手搓了一个包含 100 个样本的数据集,并在训练循环中通过索引 data[i] 逐个获取数据。
这种方式在写简单 Demo 时还凑合,但在真实的深度学习任务中,往往面临着几十 GB 甚至 TB 级别的数据。把它们一次性全塞进内存里显然是不卫生且不可行的;而且我们还需要对数据进行打乱(Shuffle)、分批次(Batching)、并行加载等复杂操作。
为了优雅地解决这些问题,PyTorch 提供了两个极其核心的工具类:Dataset 和 DataLoader。
1. Dataset 数据集
torch.utils.data.Dataset 是一个抽象类,用于表示你的数据集。你可以把它理解为一个“数据字典”。 只要你继承了这个类,并且实现了两个核心魔法方法,PyTorch 就承认这是一个合法的 Dataset:
__len__: 告诉系统这个数据集一共有多少个样本。__getitem__: 告诉系统当给定一个索引idx时,应该返回什么样的数据和标签。
下面我们来正统地定义一个自定义数据集:
import torch
from torch.utils.data import Dataset
class MyCustomDataset(Dataset):def __init__(self, num_samples=1000):super().__init__()
# 在 __init__ 中通常进行数据路径的加载、文件名的读取等轻量级操作# 这里为了演示,我们直接生成一些模拟的特征和标签
self.num_samples = num_samples
self.features = torch.randn(num_samples, 10) # 10维特征
self.labels = torch.randint(0, 2, (num_samples,)) # 0或1的二分类标签def __len__(self):# 返回数据集的总大小return self.num_samples
def __getitem__(self, idx):# 根据索引 idx 获取单个样本# 实际应用中,这里经常会写读取硬盘图片、进行数据增强(Transforms)的代码
feature = self.features[idx]
label = self.labels[idx]
return feature, label
# 实例化数据集
my_dataset = MyCustomDataset(num_samples=100)
print(f"数据集大小: {len(my_dataset)}")
# 测试抽取第 0 个样本
first_feature, first_label = my_dataset[0]
print(f"第一个样本特征 shape: {first_feature.shape}, 标签: {first_label}")2. Dataloader 数据加载器
有了 Dataset 之后,我们虽然可以按索引拿数据了,但每次只能拿一条。在训练模型时,我们需要按批次(Batch)输入数据计算梯度以加速训练,并且在每个 Epoch 开始前最好把数据打乱。
torch.utils.data.DataLoader 就是干这个的。它包装了 Dataset,在后台帮你处理所有的批次拼接、打乱以及多进程加载工作。
from torch.utils.data import DataLoader
# 将之前定义好的 dataset 喂给 DataLoader# batch_size=16 意味着每次吐出 16 个样本
# shuffle=True 意味着在每个 epoch 开始时打乱数据顺序# num_workers=2 意味着开启两个后台进程来加速数据读取(Windows下有时容易报错,通常设为0即可)
train_loader = DataLoader(dataset=my_dataset, batch_size=16, shuffle=True, num_workers=0)
# DataLoader 是一个可迭代对象,可以直接用 for 循环遍历for batch_idx, (batch_features, batch_labels) in enumerate(train_loader):
print(f"Batch {batch_idx}:")
print(f" Features shape: {batch_features.shape}") # 形状会变成 (16, 10)
print(f" Labels shape: {batch_labels.shape}") # 形状会变成 (16,)# 模拟只打印第一个 batch 就退出break3. 将 DataLoader 融入训练循环
使用了 DataLoader 后,我们之前的训练循环就可以彻底抛弃难看的手动索引了。代码会变得异常干净且高效:
import torch.nn as nn
from torch.optim import SGD
model = nn.Linear(10, 2)
loss_function = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-3, momentum=0.9)
epochs = 5
for epoch in range(epochs):
total_loss = 0.0# 直接遍历 DataLoader,它每次会自动给你一个 batch 的数据!for batch_features, batch_labels in train_loader:
# 1. 前向传播
pred = model(batch_features)
# 2. 计算损失
loss = loss_function(pred, batch_labels)
total_loss += loss.item()
# 3. 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss = total_loss / len(train_loader) # 除以 batch 的总数
print(f"Epoch {epoch + 1}/{epochs} - Average Loss: {avg_loss:.4f}")至此,从损失函数、自动求导、优化器再到数据组织,构成了一个完整的 PyTorch 基础训练流水线。
Quick Start
下面, 我们使用一个例子来快速了解一下一个PyTorch深度学习应用的组成. 熟悉PyTorch.
之前我们搞过线性回归波士顿房价. 我们在第三章的实践中(如果你做了实践), 我们使用numpy实现了一个手写数字识别任务的训练. 现在我们使用PyTorch实现一个相同的任务.
定义模型
首先我们要定义模型(本质是一个nn.Module):
import torch
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self) -> None:
super().__init__()
# 手写数字图片大小是 28x28,展平后是 784 维的一维向量
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(784, 256)
self.linear2 = nn.Linear(256, 128)
self.linear3 = nn.Linear(128, 10)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x数据准备与组织
现在我们需要准备数据. 我们直接使用torchvision来下载MNIST数据集.
from torchvision import datasets, transforms
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)我们获取到了一个torch中的Dataset类对象train_dataset. 接下来我们使用dataloader来包装它.
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)实例化模型, 损失函数与优化器
接下来我们定义模型, 损失函数与优化器. 做好训练准备.
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)加速设备识别与迁移
我们经常需要识别所运行的平台拥有什么样的加速硬件, 然后再将模型等张量迁移到设备上来调用硬件加速计算能力. 如果未检查到硬件, 我们应该回退到cpu上(提升代码鲁棒性).
def get_device():
if torch.cuda.is_available():
device = torch.device('cuda')
print(f"已挂载 GPU: {torch.cuda.get_device_name(0)}")
elif torch.backends.mps.is_available():
device = torch.device('mps')
print("已挂载 Apple MPS 加速")
else:
device = torch.device('cpu')
print("未检测到加速硬件,使用 CPU 进行计算")
return device
device = get_device()
model.to(device)下面是训练代码:
from tqdm import tqdm
epoch = 5
for _ in range(epoch):
model.train()
train_pbar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{epochs} [Train]')
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_pbar.set_postfix({'loss': f'{loss.item():.4f}'})
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
test_pbar = tqdm(test_loader, desc=f'Epoch {epoch+1}/{epochs} [Test ]')
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\n>>> Epoch {epoch+1} Summary: Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%\n')模型保存
一般来说,我们保存模型时保存该模型的state_dict。state_dict是一个Python字典,保存了模型的“状态”。这个状态包含了模型的结构,以及这个结构的参数。例如,我们如果查看刚刚训练的模型的state_dict,是这样的:
print(model.state_dict())不只是模型,优化器也是可以保存state_dict的。
print(optimizer.state_dict())保存state_dict可以使用torch.save函数,其本身会调用pickle进行序列化保存。
PATH = r'./model.pt'
torch.save(model.state_dict(), PATH)加载模型进行推理
模型的参数与模型的“类”是分开保存的。所以需要向一个创建好的对象导入state_dict。不过在此之前,先要用torch.load把路径中的文件读出来,变成Python字典对象:
model = MLP()
state_dict = torch.load(PATH)
mode.load_state_dict(state_dict)