第三章 NumPy, 使用计算机进行线性代数计算
在第一章中, 我们介绍了线性代数表示的神经网络计算. 而在第二章我们又学习了 Python. 大家都说 AI 是用 Python 写的. 那很好, 我们现在开始用 Python 写神经网络吧!
根据一点点程序设计的基本思想, 我们肯定希望类似矩阵乘法, 矩阵加法的操作封装好, 封装成函数, 最好还可以把向量, 矩阵用类封装(面向对象). 不过, 肯定有库实现了这些东西. 但在这里, 为了课程的继续, 我们还是尝试自己实现一下. 这里直接用列表表示向量, 嵌套列表表示矩阵:
from typing import List
def matmul(mat1: List[List[float]], mat2: List[List[float]]) -> List[List[float]]:
r1, c1 = len(mat1), len(mat1[0])
r2, c2 = len(mat2), len(mat2[0])
assert c1 == r2 # 形状检查
result = [[0. for _ in range(c2)] for _ in range(r1)]
for i in range(r1):
for j in range(c2):
for k in range(c1):
result[i][j] += mat1[i][k] * mat2[k][j]
return result
mat1 = [
[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]
]
mat2 = [
[0.1, 0.4, 0.2],
[0.2, -0.5, 0.7],
[-0.1, -0.2, -0.3]
]
print(matmul(mat1, mat2))但是, 我们可以看出来, 这个实现非常麻烦. 我们需要自己检查形状等等. 最关键的是, 这个实现效率是极低的! 以一个输入层大小 784, 隐藏层大小 2048, 输出层大小 10 的 MLP 举例, 最大的矩阵乘法要处理一个(batch_size, 784)和(784, 2048)大小的矩阵相乘. 这在现代处理器上其实也没有什么压力. 我们跑一个测试(假设 batch_size 是 32):
import time
batch_size: int = 32
mat1 = [[0.1 for _ in range(784)] for _ in range(batch_size)]
mat2 = [[0.1 for _ in range(2048)] for _ in range(784)]
t1 = time.time()
matmul(mat1, mat2)
t = time.time() - t1
print(t)这在我的机器上花费将近 3 秒(2.8159382343292236)! 这太慢了. 这还只是一个玩具级的网络(即使对我的 CPU 来说, 也是玩具级的). 造成这种缓慢的问题有很多, 感兴趣的同学可以查询相关资料. 这里我们解释为 Python 作为解释器速度天然有劣势, 并且需要维护很多对象, 列表本身是个动态还不连续的结构, 并且 Python 存在 GIL(全局解释器锁)使得程序只能单线程.
于是, 有人(一群人)专门为 Python 实现了一个高性能的线性代数库 NumPy. NumPy 是由 C 编写的, 进行了很强的优化, 然后暴露接口给 Python 调用.
虽然还没介绍 NumPy 的语法, 但是这里对比一下时间, 给大家看一下性能差距:
import numpy as np
batch_size: int = 32
# 随机生成两个矩阵
mat1 = np.random.rand(batch_size, 784)
mat2 = np.random.rand(784, 2048)
import time
t1 = time.time()
for _ in range(1000): # 这里因为numpy太快了所以测1000次求平均
np.matmul(mat1, mat2)
t = time.time() - t1
print(t/1000)在我的机器上, 这个时间是 0.0015103209018707275 秒, 快了 1866 倍!
实际情况下快不了这么多, 这里 1000 次测试缓存命中率太高了.
NumPy 介绍
https://numpy.org/. NumPy 是一个很活跃的 Python 高性能计算库.
NumPy 语法入门
NumPy 的语法尽量贴合 Python 原版的列表. 在这里, 我们先介绍基本的 NumPy 对象: NdArray.
NdArray
ndarray 是 numpy 中用于表示向量, 矩阵, 张量的类型. 其存储在一段连续的内存上. 定义 ndarray 有许多种方法. 这里先使用最简单的.
import numpy as np
vec = np.array([1, 2, 3, 4])
mat = np.array([[1, 2, 3],
[4, 5, 6]])
print(vec)
print(mat)定义时, 可以传入 dtype 参数, 用于指定存储类型. 与列表不同, ndarray 中必须全部元素是相同类型. 如果不传入该参数, 类型将自动判断.
以下是可用的参数(这里只列出 numpy 的标准类型, 我们也推荐使用这种方式定义类型):
| **对象** | **含义** |
| np.int8 | 8位有符号整数 |
| np.int16 | 16位有符号整数 |
| np.int32 | 32位有符号整数 |
| np.int64 | 64位有符号整数 |
| np.uint8 | 8位无符号整数 |
| np.float32 | 单精度浮点数 |
| np.float64 | 双精度浮点数 |
| np.bool_ | 布尔类型 |
| np.complex64 | 复数 |
| np.str_ | 长度为10的unicode字符串 |
| np.bytes_ | 长度为10的字节字符串 |
下面是一个类型定义示例:
import numpy as np
vec = np.array([1, 2, 3, 4], dtype=np.int8)
mat = np.array([[1, 2, 3],
[4, 5, 6]], dtype=np.float32)
print(vec)
print(mat)在所有类型中, 我们最经常使用的是 float32.
定义特定 NdArray
有时候, 我们需要定义一些特殊的 array, 例如全是 0, 全是 1, 或者是我们根本不关心数据, 我们只想要一块特定形状的 array, 用来存放中间结果之类的.
定义全 0 的 array, 我们使用 np.zeros 函数:
import numpy as np
arr = np.zeros((2, 3, 4), dtype=np.float32)
print(arr)定义全 1 的 array, 我们使用 np.ones 函数:
import numpy as np
arr = np.ones((4, 3, 2), dtype=np.uint8)
print(arr)我们不关心具体的值, 只希望要一个特定的形状, 可以使用 np.empty 函数. 这可以减少赋值的开销.
import numpy as np
arr = np.empty((3, 4, 5), dtype=np.float32)
print(arr)NdArray 索引访问
ndarray 的索引访问几乎与嵌套列表是相同的. 但是也有一些区别.
import numpy as np
vec = np.array([1, 2, 3, 4, 5], dtype=np.float32)
vec[1] = 0.1
print(vec)
mat = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
print(mat[1])
print(mat[1][2])
print(mat[1, 2])
print(mat[:, 1])
tensor = np.array([
[[1, 2, 3],
[4, 5, 6]],
[[-6, -5, -4],
[-3, -2, -1]]
], dtype=np.float32)
print(tensor[1, :, 1]): 的含义是"全取". 以此来实现更加灵活的访问.
NdArray 的计算
首先是基本的线性代数计算. NumPy 肯定是支持的.
import numpy as np
mat1 = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
mat2 = np.array([[-1, -2], [-3, -4], [-5, -6]], dtype=np.float32)
mat3 = np.array([[-1, -2, -3], [-4, -5, -6]], dtype=np.float32)
print(mat1.shape, mat2.shape, mat3.shape)
print(mat1 + mat3)
print(mat1 - mat3)
print(mat1 * mat3)
print(mat1 / mat3)
print(mat1 @ mat2) # np.matmul(mat1, mat2)numpy 还支持求最大/小值, 求最大/小值索引:
import numpy as np
tsr = np.random.rand(2, 3, 4)
tsr[0][1][2] = 100
print(np.max(tsr))
print(np.argmax(tsr))numpy 中可以方便转置, 转置操作是很便宜的. 因为它只会修改元信息.
a = np.array([[1, 2, 3], [4, 5, 6]]) # shape (2, 3)
print(a)
print(a.shape)
b = a.T # 转置,shape (3, 2)
print(b)
print(b.shape)
# 转置只是修改了 strides 和 shape 的读写顺序,不涉及数据拷贝
# 可以验证:a 和 b 共享同一块内存
a[0, 0] = 100
print(b[0, 0]) # 输出 100,说明确实共享内存Broadcast 广播机制
Broadcast 广播机制是一个非常重要的机制. 其基本机制十分简单.
我们知道, ndarray 的加减乘除都是要求形状匹配. 例如对应位置加减乘除需要两个数组形状一样, 矩阵乘法要求最后两个维度满足矩阵乘法的形式, 前面的维度要一致. 但是假如我们想要实现这样一个操作: 向量
但是这样其实不太好. 因为它占用了更多的存储空间, 拷贝也会有开销. 实际上我们可以让计算机直接做这件事情. NumPy 为了让用户可以实现这样的操作, 提供了广播机制.
当一个操作的输入数组形状不匹配时, numpy 会进行广播机制判定, 它的规则如下:
- 将所有输入数组的维数补全到维数最大的那个数组. 补全的方式为在前面加 1. 例如, 三个输入数组的形状分别为(2, 3), (2, 3, 4), (2, 3, 4, 5), 则会被补全成(1, 1, 2, 3), (1, 2, 3, 4), (2, 3, 4, 5).
- 检查每个输入数组的维度. 如果维度大小是相同的, 则没事. 如果维度大小不同, 并且其中一个数组的维度是 1, 则触发广播机制, 也是合法的. 对应维度大小为 1 的那个数组将在该维度上被广播. 否则输入不合法. 例如形状(1, 3, 4)和(5, 3, 1)是合法的一组输入. 输入形状(1, 2, 3)与(3, 2, 2)不合法.
广播机制实际上不会对数据进行复制, 因此效率比拷贝方法高, 而且内存开销也小.
多查资料多问 AI
NumPy 中的细节真的非常多. 而且目前的教育中, 有关矩阵的讨论是很少的. 使得多维数组的操作实际上是一门学问, 并且大家比较欠缺这方面的经验. 课程中不可能全部涉及到. 甚至说, 这里提到的相关知识, 只是 NumPy 最基础的一些概念, 而你往往需要进行一些不太寻常的多维数组操作, 你就需要去寻找 numpy 是否提供了一些接口, 你如何使用这些接口来达成你的目的. 并且, 这个部分的很多东西思考起来是很反人类的.
这就需要大家多去查资料, 多去问 AI. 很多细节并不复杂, 是一个知不知道的问题.
NumPy 实现线性回归波士顿房价
线性回归
我们在高中都学习过线性回归方法. 这里介绍其更加通用的形式, 即多元的情况.
我们的场景中存在
写成线性代数形式:
其中,
为了方便计算, 这里引入一些概念. 我们先将
我们把所有数据集中样本特征拼成一个矩阵, 称之为设计矩阵
预测值可以写为:
我们使用均方损失, 尝试找到最优参数
微分:
有关
因此,
令梯度为
我们得到了在均方损失意义下最好的参数:
波士顿房价
波士顿房价是一个很经典的机器学习任务. 波士顿房价的任务如下:
我们都知道房价肯定和附近基础设施, 距离城市中心的距离等因素有关, 但是我们在生活中一般是定性分析的. 但是我们想要更加详细地研究房价问题. 有人统计了波士顿附近多个房子的相关属性, 每个房子收集十三个可能影响房价的特征. 特征如下:
| **特征名称** | **含义** |
| CRIM | 城镇人均犯罪率 |
| ZN | 占地面积超过25,000平方英尺的住宅用地比例 |
| INDUS | 城镇非零售商业用地比例 |
| CHAS | 是否靠近查尔斯河(0代表不靠近, 1代表靠近) |
| NOX | 一氧化氮浓度 |
| RM | 每栋住宅的平均房间数 |
| AGE | 1940年之前建成的自用住房比例 |
| DIS | 到波士顿五个就业中心的加权距离 |
| RAD | 径向高速公路可达性指数 |
| TAX | 每10,000美元的全额财产税率 |
| PTRATIO | 城镇师生比例 |
| B | 城镇黑人比例 |
| LSTAT | 低收入人口比例 |
我们的目标变量是 MEDV, 含义是自住房屋的中位数价值.
任务分析
我们将使用线性回归方法来预测 MEDV. 首先我们定义线性回归模型的输入, 即特征向量:
我们定义模型的参数:
我们将数据集中所有样本的 MEDV 值组织成标签向量:
所有样本的特征向量组织成设计矩阵:
我们就可以直接计算出最优参数
代码实现与分析
实现线性回归模型类.
这里我们先实现一个线性回归类:
import numpy as np
class LinearRegression:
def __init__(self, n: int) -> None:
self.n = n
self.w = np.empty(n+1, dtype=np.float32)
def __call__(self, X: np.ndarray) -> np.ndarray:
assert X.shape[1] == self.n + 1
return np.matmul(self.w, X.T)
def fit(self, features: np.ndarray, labels: np.ndarray) -> None:
self.w = labels @ features @ np.linalg.inv(features.T @ features)我们需要加载波士顿房价数据集. 由于一些不能说的原因, 波士顿房价数据集无法在新版本的 sklearn 库中直接导入. 我们准备好了波士顿房价的数据集, 从本地导入.
FILE = r'./boston_data.csv'
boston_data = np.loadtxt(FILE, delimiter=',', skiprows=1, dtype=np.float32)
print(boston_data.shape)这个 csv 文件是这样组织的:
我们跳过了第一行, 因为第一行是字符, 无法转化为 np.float32.
接下来, 我们分离特征与标签, 训练集与测试集. 这里测试集按照 20% 划分.
SAMPLE_NUM = boston_data.shape[0]
TRAIN_SAMPLE_NUM = int(SAMPLE_NUM * 0.8)
train_features = boston_data[:TRAIN_SAMPLE_NUM, :13]
train_labels = boston_data[:TRAIN_SAMPLE_NUM, 13]
print(train_features.shape, train_labels.shape)
test_features = boston_data[TRAIN_SAMPLE_NUM:, :13]
test_labels = boston_data[TRAIN_SAMPLE_NUM:, 13]
print(test_features.shape, test_labels.shape)注意, 特征向量需要在最前面补 1, 进行特征扩展.
train_features = np.concatenate((np.ones((TRAIN_SAMPLE_NUM, 1), dtype=np.float32), train_features), axis=1)
test_features = np.concatenate((np.ones((SAMPLE_NUM - TRAIN_SAMPLE_NUM, 1), dtype=np.float32), test_features), axis=1)
print(train_features.shape, test_features.shape)
print(train_features[:5])
print(test_features[:5])然后是拟合部分的代码
model = LinearRegression(13)
model.fit(features=train_features, labels=train_labels)
predict = model(test_features)使用 matplotlib 库进行图像绘制:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.plot(test_labels, label='True Value', color='r', alpha=0.7)
plt.plot(predict, label='Prediction', color='b', linestyle='--', alpha=0.7)
plt.title('Boston Housing: Prediction vs True Value')
plt.xlabel('Sample Index')
plt.ylabel('Price')
plt.legend()
plt.show()结果如下:
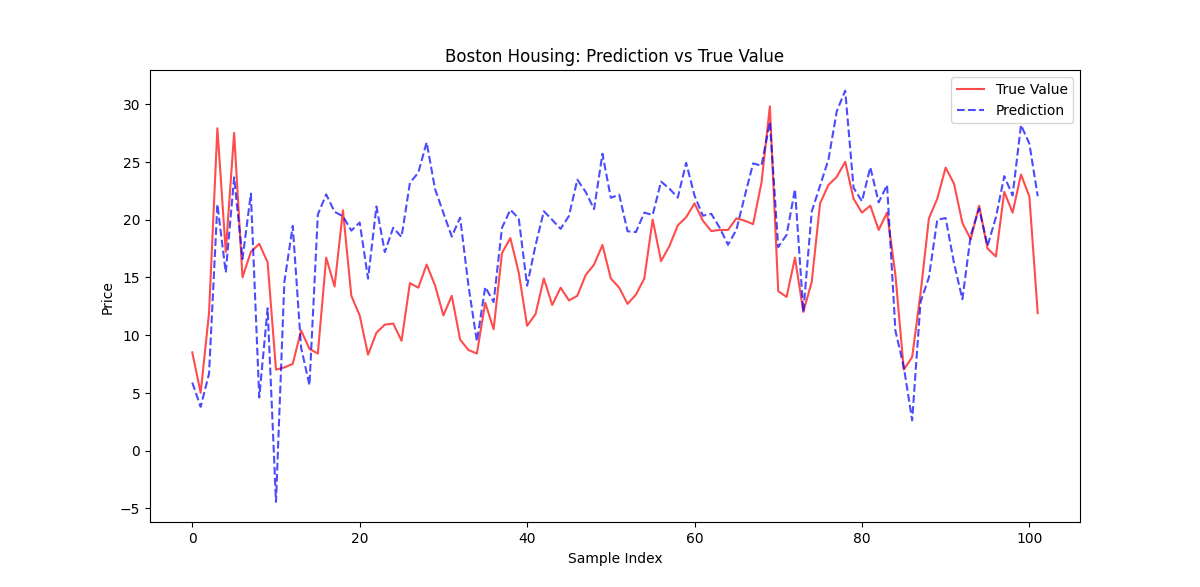
可以看到效果还行.