第五章 计算机视觉
顾名思义,就是让计算机看见东西。想要让计算机拥有视觉,或许最好的方式是使用一些仿生学的原理,来看看自然界里已有的动物们是如何拥有对于视觉的感知的。
1959年,哈佛大学的大卫·休伯尔(David Hubel)和托斯坦·威塞尔 (Torsten Wiesel) 进行了一项研究。他们将极其微细的电极插入一只被麻醉猫的初级视觉皮层。猫面对着一个屏幕,研究员用投影仪在屏幕上打出不同形状和大小的黑白光斑,试图观察特定神经元的放电反应。但无论光斑怎么变化,监测仪上的神经元都几乎毫无反应。当威塞尔将一张带黑点的玻璃幻灯片插入投影仪插槽时,玻璃边缘在屏幕上扫过的一瞬间,微电极却突然检测到了很大的电平变化。这意味着,让神经元兴奋的是移动的直线边缘,而不是光斑本身。他们发现了视觉皮层神经元的两类核心细胞和机制。第一类是简单细胞,这类细胞只对特定角度、特定位置的线条敏感。第二类是复杂细胞,这类细胞接收来自多个简单细胞的信号。它们同样对线条的特定方向敏感,但对位置不再挑剔。
这个实验告诉我们,视觉是一个自底向上的多层特征抽象过程。视网膜捕捉光信号,简单细胞提取局部边缘,复杂细胞提供对于不同位置的边缘的处理,然后信号被传递到更高层的脑区,将这些基础边缘组合成轮廓、形状、纹理,最终拼凑出对物体的整体认知。这样的结论在某种程度上也启发了人工智能领域的研究。在我们稍后介绍的CNN当中,你会看到,简单细胞对应了卷积层,通过不同的卷积核提取图像的边缘和轮廓,复杂细胞的位置不敏感性则对应了池化层,赋予了模型一定程度的平移不变性。
那么,让我们首先看看计算机视觉到底干些什么。
最基本的,让计算机拥有从视觉分辨物体的能力!让计算机能够分辨墙壁和地面,猫和狗,0-9的数字……这些都是计算机视觉领域非常基础的任务,即图像识别,最基本的形式是,给计算机一张完整的图片,判断它属于哪个类别。在那之后,图像分类也衍生出了各种各样的任务,有时候我们想要知道物体在图像中的具体坐标,有些时候我们让计算机指出图像中的每一部分分别是什么物体。这些场景都可以大致被归入识别任务的范畴。
然后,我们希望计算机能够生成图像。最早的时候,我们给计算机一系列图片,然后想要它生成出相似的图片。后来加入了明确的输入和参考,任务变成了改图。例如超分辨率重建、图像去噪、黑白照片上色,进阶的比如图像修复和风格迁移。后来我们把任务扩展到了自然语言,希望模型可以接受输入的自然语言,然后能够生成图像。
通道,特征,特征图
在真正开始之前,我们需要先解释一些计算机视觉的术语:通道,特征和特征图。
通道的含义非常简单,你可以把它看做是图像的某一个位置对应了多个信息,或者是几张图片堆叠在一起。对于最常见的 RGB 图像,它有 3 个通道,你可以想象它其实是由红、绿、蓝三种颜色的图片构成的,最后三张压成一张显示出来。随着网络加深,通道不再代表颜色,而是代表特定的特征属性。有的通道可能专门负责检测垂直边缘,有的通道负责检测圆形轮廓,诸如此类。
特征是数据中具有辨识度的信息提取。线条、边缘、斑点、纹理、部件(如眼睛、车轮)、语义概念(如人脸、汽车、猫)。从低级到高级,从具象到抽象,这些都属于特征的范畴。越具象的特征是越好提取的,你很容易描述出什么是线条,什么是斑点。而越抽象的、离最终的任务越近的特征是越难提取的,你很难完整的表达出如何从图片中识别一只猫。大多数基于神经网络的计算机视觉方法,都是想办法从图像中一步步提取出高级的特征。
特征图是卷积运算的输出结果。如果一个卷积核专门检测横向边缘,那么经过它处理后生成的二维矩阵就是一张横向边缘特征图。在这个图里,数值高的地方表示该位置存在明显的横向边缘,数值低的地方则没有。
卷积
我们接下来将要讲到的一个重要主题是CNN。CNN的意思是卷积神经网络。「卷积」!听起来就像是某种高级的数学方法一样。但是请你先不要去查找卷积的数学含义,那大概率只会让你更加难以理解CNN。在AI的世界里,卷积只是一种非常直观的处理图像的方式。
我们把输入的图像表示为一个矩阵,上面写着的数字对应了每个像素的值。然后我们用它和另一个被称为「核函数」(有些时候也叫卷积核)的矩阵进行一些奇妙的运算,规则是这样的:
把核函数矩阵叠放在输入的左上角,让重叠区域中输入矩阵的数字和核函数里对应位置的数字相乘,这样,重叠区域的每一格都有一个对应的结果。我们把结果加在一起,写下来,这就是图中的19。
然后,我们挪动核函数,把它放在所有可能的位置。计算得到他们分别的输出。我们把每次放下核函数计算得到的结果写在输出矩阵里和核函数的位置相对应的地方。
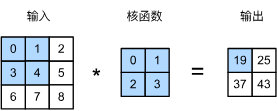
输出矩阵中的每一个像素其实是综合了多个原始的输入像素得出的。至于怎么综合,就由核函数来决定。在CNN出现以前,卷积就已经作为一种图像处理的方法存在了,利用它可以对图像进行模糊处理、提取边缘,等等等等。这个网站提供了一些示例的图片,还有可以自定义的核,你可以选择一个知名的核函数,看看它是否能够和它的描述一样对图像进行处理,或者自己调出一个核函数,看看它的效果。

这是一个例子,如果你像这样设置核函数,你会发现图像变得漆黑一片,只留下了竖直的边缘。多么高效的方法!仅仅是调了几个数字,我们现在让计算机能够看出来哪些线条是竖着的了。这还是太人工了,不妨让它变得智能一点。
深度学习的方法,本质上就是让计算机自己调整参数。如果能让它自己调出合适的卷积核就更好了。
没错!待会你会看到,CNN中的卷积核是一个非常重要的可学习参数。模型可以在训练中决定自己想要用卷积提取的是怎样的纹理。
汇聚(池化)
卷积的一个重大作用是增大感受野。卷积结果中的一个像素来源于输入的一片区域,而如果我们把这个卷积的结果再送去卷积,得到新的卷积结果,那么这个新的卷积结果实际上来源于最初输入的相当大的一片区域。这个区域就被叫做感受野。感受野的大小决定了模型能够在多大程度上看到全图的信息。很多模型对图像做几十上百次的卷积,就是为了扩大模型的感受野。但是,堆叠卷积层在计算量上对模型提出了挑战。有没有什么办法,既能够很快地增加感受野,又不用增加新的参数?
人们发明了汇聚。一般的汇聚分为最大汇聚和平均汇聚,汇聚的计算方法非常简单,选定一个区域,在其中计算最大值或者平均值,然后在输入上移动这个区域,得到结果。
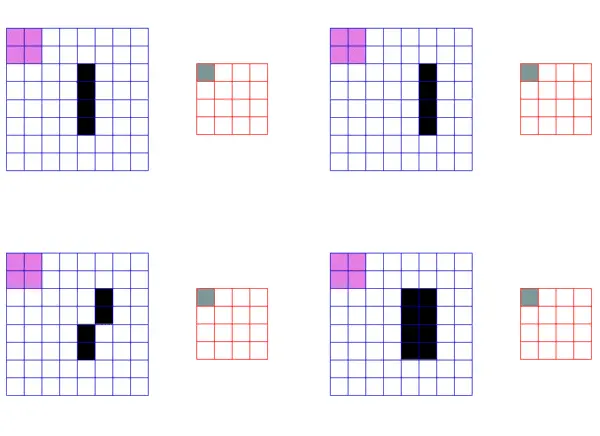
在图上你可以看到,一张88的图像在经过了22的最大池化之后,变成了一张44的图像。也就是说,这个44的图像聚合了原有的8*8输出的内容。相比CNN ,图像的大小减小得更迅速了,这意味着感受野的增大也更加迅速。聚合的另一个作用是提供一些平移不变性。就像动图所展示的那样,几个输入虽然有细微的不同,但是他们经过池化后的输出是一样的。这样的稳健性也会带来代价,比如模型对于细节特征的感知能力可能就没有那么好。
CNN 卷积神经网络
了解了卷积和汇聚,我们就可以合成一个CNN了。LeNet是最早发布的CNN之一,因其在计算机视觉任务中的高效性能而受到广泛关注。它的结构是这样的:
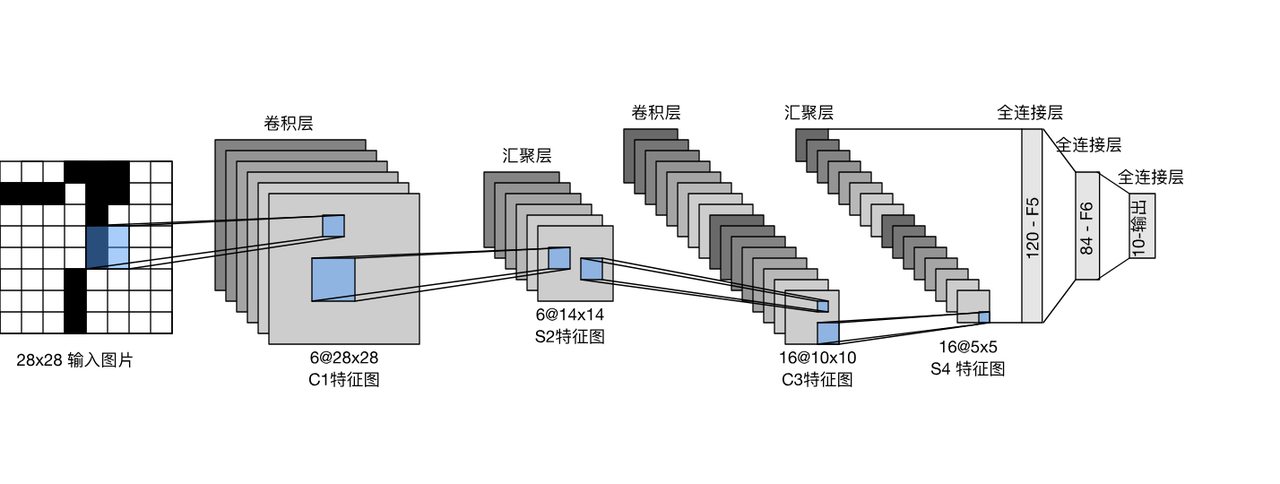
图里诸如6@2828这样的标记,表示有6张2828的特征图。对于图里的第二个卷积层,它的输入是6张S2特征图。因此,它的每个卷积核都是具有6个通道的,相当于6个二维的卷积核叠在一起,它们会分别和输入做卷积运算。使用16个这样的卷积核,就得到了16@10*10的C3特征图。为了让模型具备非线性,我们在每一个卷积层后面加上一个激活函数,它会对每一个像素单独做运算。在最后一层汇聚层之后,我们把二维矩阵中的元素全部排列成一个向量,这个操作被称为展平。在这里,模型已经提取出足够高级的特征,我们用几个全连接层来对这些特征做聚合,并得到最终的结果。结果是一个10维的向量,每个位置上代表了当前数字分别是0~9的概率。我们把LeNet加深,就得到了AlexNet,这也是非常有名的CNN。

VGG通过不断重复一个预制的块把网络的深度进一步加深了,然而就在这里,出现了问题。

还记得第四章当中的链式法则吗?神经网络实际上是一个嵌套的函数,当我们求导的时候,我们是对这一个链当中的每个函数分别求导,再乘在一起。问题在于,当我们扩充模型的层数之后,这个链变得相当的长。一个大的VGG是会超过100层的。假设我们有100层,那么当我们想要求第一层中某个参数对于损失函数的偏导数,就必须乘上后面99层的导数。假如后面99层的导数都是0.9,我们就会得到2.546295e-10这样极小的数字,在之后的参数更新当中,这个参数几乎不会被更新。而且,在计算机的世界中,我们事实上不能表示一个无限小的数字,如果它超出了浮点数的表示范围,整个训练过程就崩溃了。这被称为梯度消失。反之如果导数太大导致梯度太大,就会产生梯度爆炸。
ResNet采取一个非常简单的方法解决了这个问题。
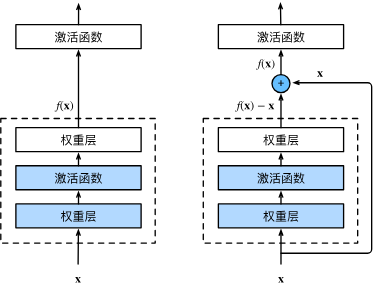
原本我们的每一层是
即便这一层的残差函数
GAN 生成式对抗神经网络
左脚踩右脚可以上天吗?GAN的回答是可以。许多人至今仍然认为GAN是他们见过最天才、最优雅的方法。GAN的全称是Generative Adversarial Network,生成对抗网络。它的想法非常有意思。我们的目标是训练一个能够生成逼真图像的网络。为了达成这个目标,我们引入另外一个称为辨别器的网络,这个网络能够辨别输入是真实的图片,还是生成的图片。然后我们把两个部分合起来。对于生成网络,它的优化目标是尽可能误导辨别器,让辨别器认为它的输出是真实的,对于辨别器网络,它的优化目标是尽可能分辨出真实和合成的图像。在这样基于博弈的训练过程当中,我们最终应该能够让生成器和辨别器都越来越强。最终,我们得到了生成足以以假乱真的生成器和能够分辨出虚假图片的判别器。
来看一点点公式吧!首先,对于判别器,我们有:
这里我们从两个数据集里采样,分别是真实数据集
而生成器的目标就非常简单了:
在
Diffusion 扩散模型
在介绍这个技术之前,我们先引入一个场景:我们观察雕塑家制作雕塑,他接收到的是一块没有意义的方正石头,他使用工具一点点把多余的部分去掉,最终剩余的部分是有意义的形状了。 我们的图像生成是否也可以这样呢?模型被输入的无意义噪声,就是"方正石头",代表无信息,没有明确的含义。而模型需要做的是作为一个雕刻家,每次只去掉一点点不需要的部分,最后剩下的就是有意义的内容。 即图片已经存在于噪声之中,只是需要模型一点点去掉多余的部分。这个过程我们称之为"去噪"。