第二章 Python 基础
Python 已经是一门非常有名的语言. 相信不少同学都听说过, 甚至有同学已经熟练掌握.
很多人认为 Python 最大的优势是简洁, 可读性强. 阅读良好的 Python 程序如同阅读英语一般. 诚然, Python 在设计上就在追求一种简洁与和谐. 但其实 Python 对于普通开发者来说最大的优点是强大的生态. 在深度学习领域, Python 是几乎所有框架的编程 API 第一选择.
就算你不做一个 AI 开发者, 你也最好学一学 Python. 这门语言本身的学习成本可以说是最低的, 而扩展又十分强大. 你需要快速搭建一个 web 应用时, 你不需要学习前端框架与 Spring, 使用 fastapi, streamlit 这些 python 库就可以迅速搭建一个基本的 web 应用. 可以这么说, Python 是最适合非程序员的语言, 也是程序员最喜欢的玩具.
Python 的历史
Python 是在 1980 年代后期所构思出来的编程语言, 并于 1989 年 12 月由荷兰 CWI 的吉多·范罗苏姆开始进行编程发展.
Python 源代码遵循 GPL(GNU General Public License)协议.
Python 2.0 版于 2000 年 10 月 16 日发布, 引入垃圾回收器.
Python 3.0 版是一个主要的"向后不兼容"(backwards-incompatible)版本, 经过长时间的测试之后, 于 2008 年 12 月 3 日发布.
现在我们所说的 Python, 大多指的是 Python3.
Python 原理直观解释
大家在程序设计课上学过, C++ 是通过编译器, 将源代码文件编译成可执行文件, 然后才能在机器上执行.
而 Python 并不使用这种方法. 它使用"解释器"来运行源代码. 这个解释器有多个实现, 例如 CPython, PyPy, Numba. 不过我们一般默认是 CPython. 当你写好 Python 源代码文件后, 使用 Python 解释器执行这个文件. 解释器会将程序"一行一行"地实时翻译成机器指令, 来使其在机器上运行.
为了方便理解, 这里并不严谨. 实际上解释器运行程序的机制较为复杂, 并不是一行一行. 而是被转换成"字节码", 类似机器指令, 随后解释器会像 CPU 执行指令一样处理字节码. 这其中, 会使用类似"指令预取"等与 CPU 类似的技术. 而 PyPy 与 Numba 的解释器实现, 使用名为 JIT(Just-in-Time Compile, 即时编译)的技术, 与 CPython 的类似 CPU 的字节码指令与"求值循环"有所区别.
因此, 运行 Python 不需要经过耗时的编译流程, 只需要等待解释器的启动, 程序就可以开始运行.
安装与环境配置
在安装 Python 之前, 先要说明:
- 你们之后实际上很少用全局环境的 Python, 也就是你待会要安装的 Python. 本课程后面会讲解 Python 虚拟环境相关的内容. 在那之后实际上大家就使用 conda 与 uv 创建的虚拟环境中的 Python 了.
- 有关环境配置中的 VsCode 相关内容. 这里假定你们已经安装了 Visual Studio Code. 注意是 Visual Studio Code, 而不是 Visual Studio. 后者就是在程序设计课上要求安装的.
Windows
不要从什么应用商店下!!!
前往 Python 官网(python.org), 找到 Downloads 页面:
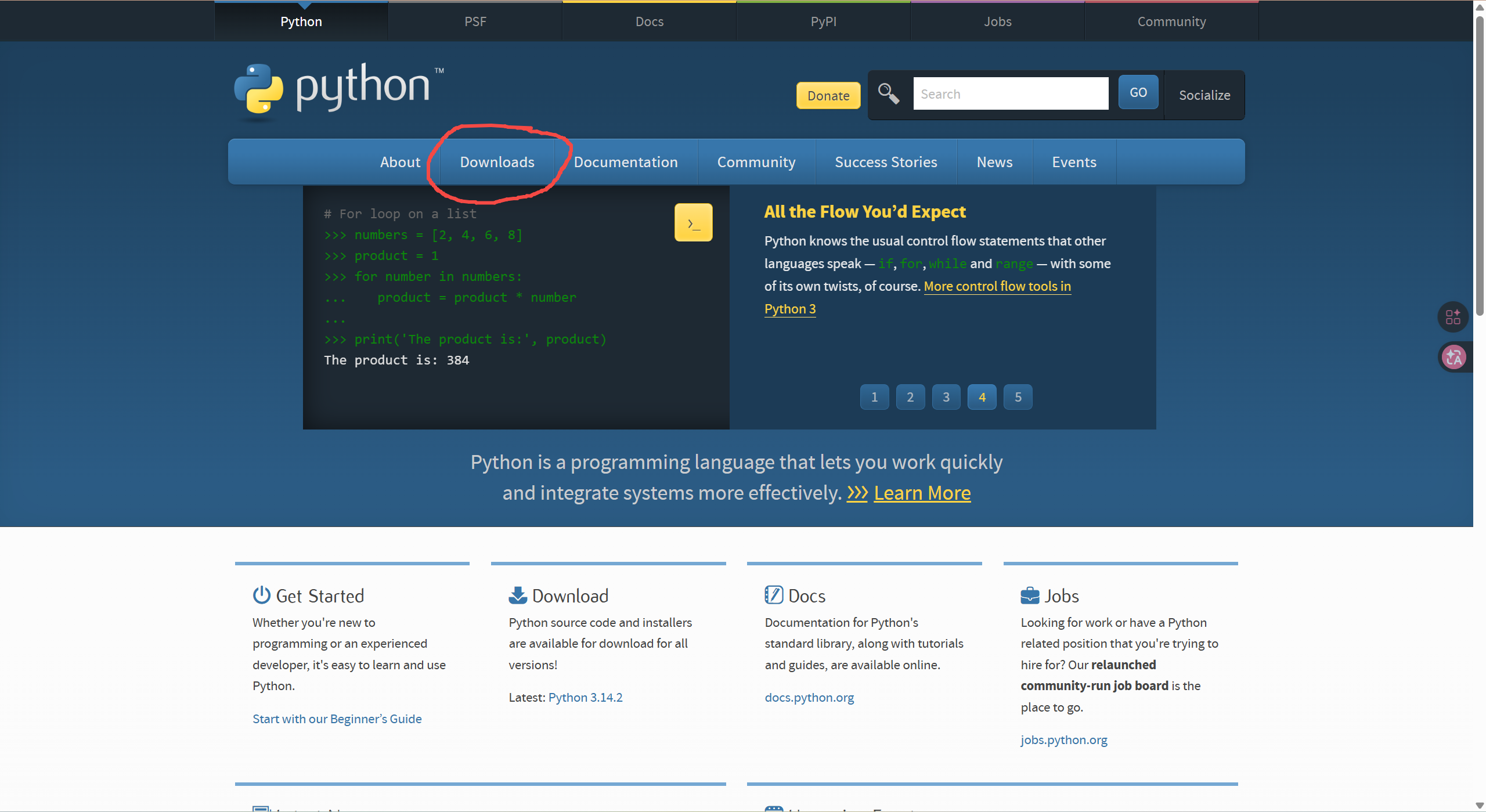
然后直接点击"Download Python install manager":
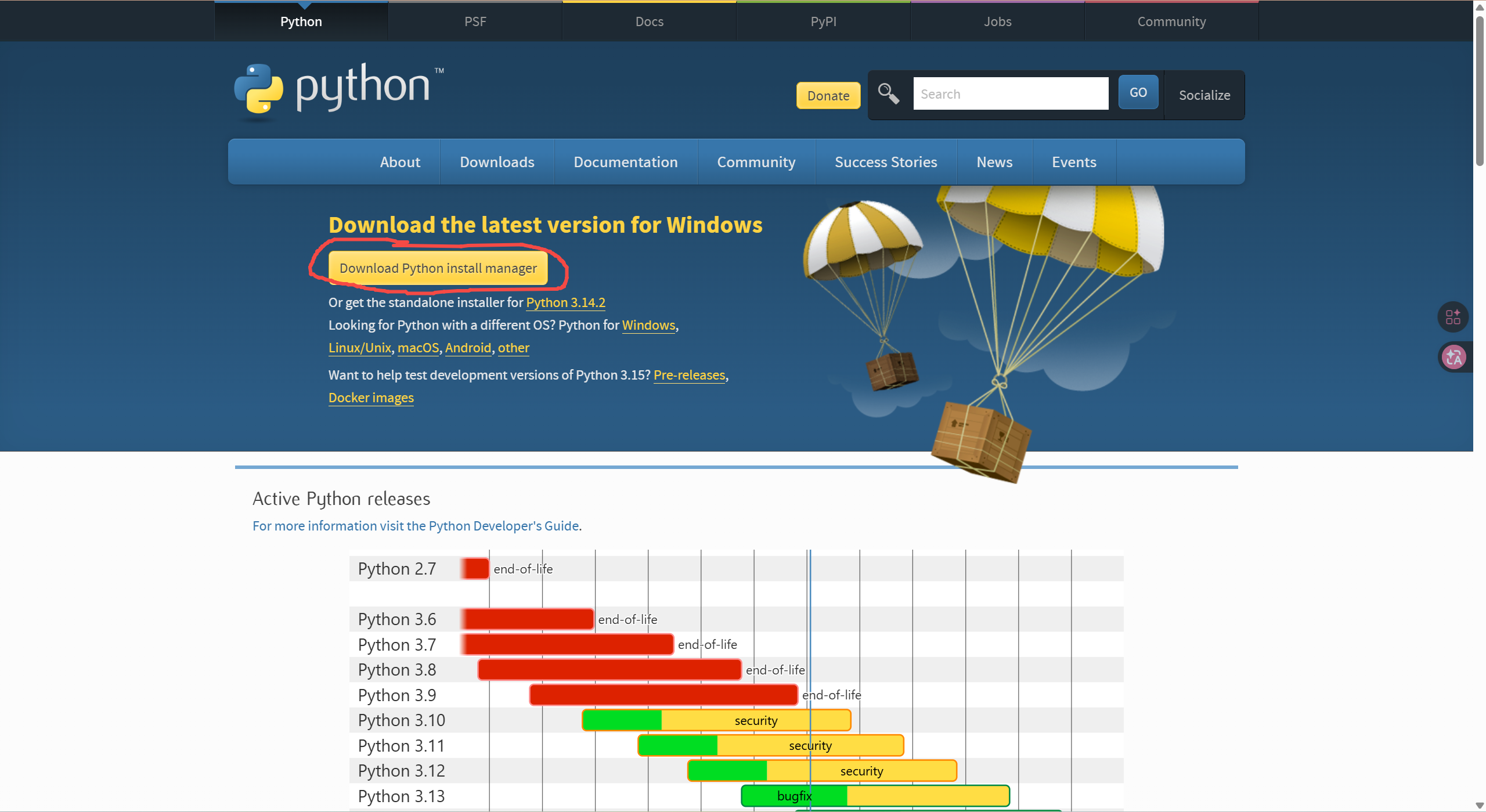
国内网络环境下载会比较慢...
[施工, 加速站点]
下载好之后, 双击运行该文件. 在弹出的窗口中点击确认.
[施工]
MacOS
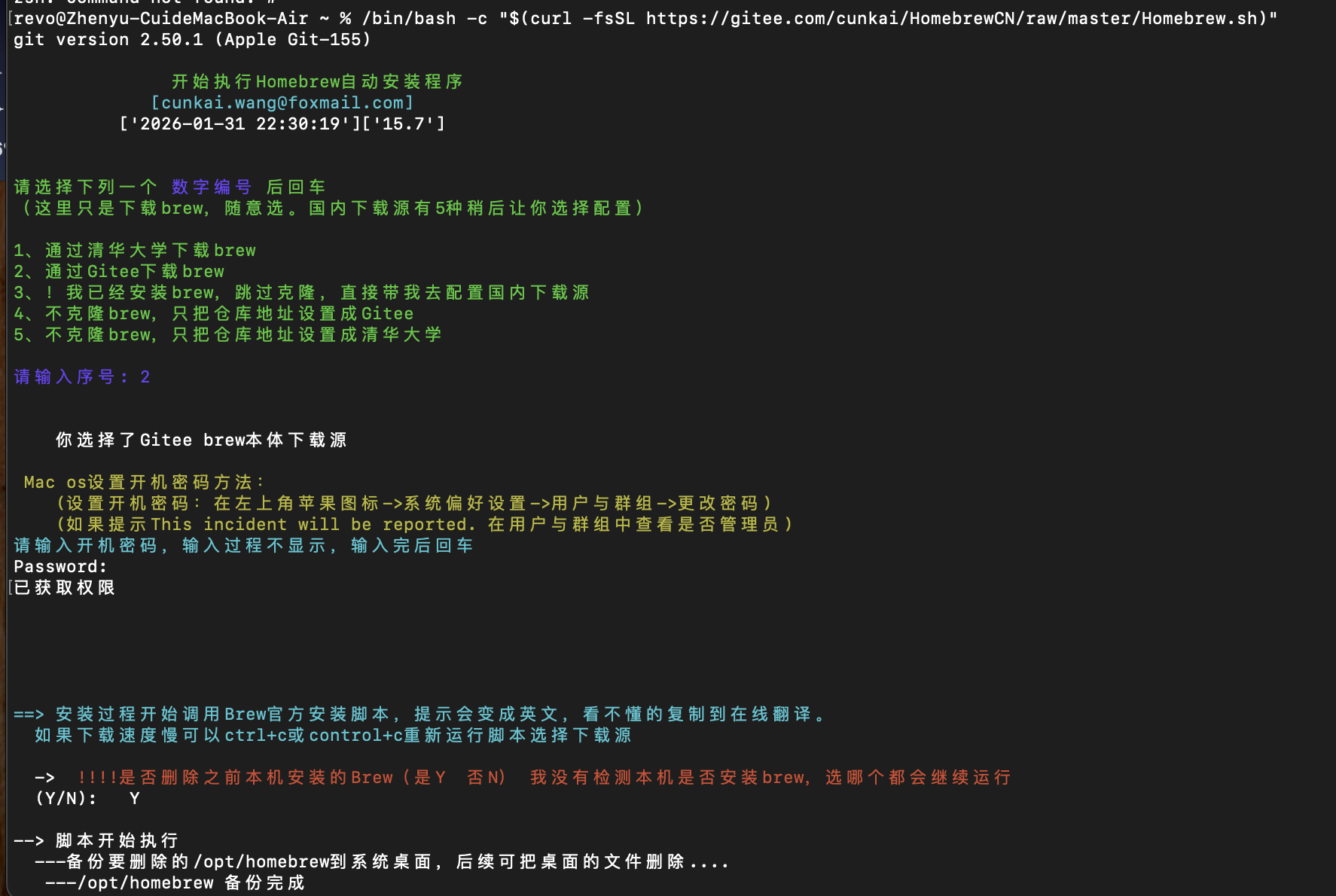
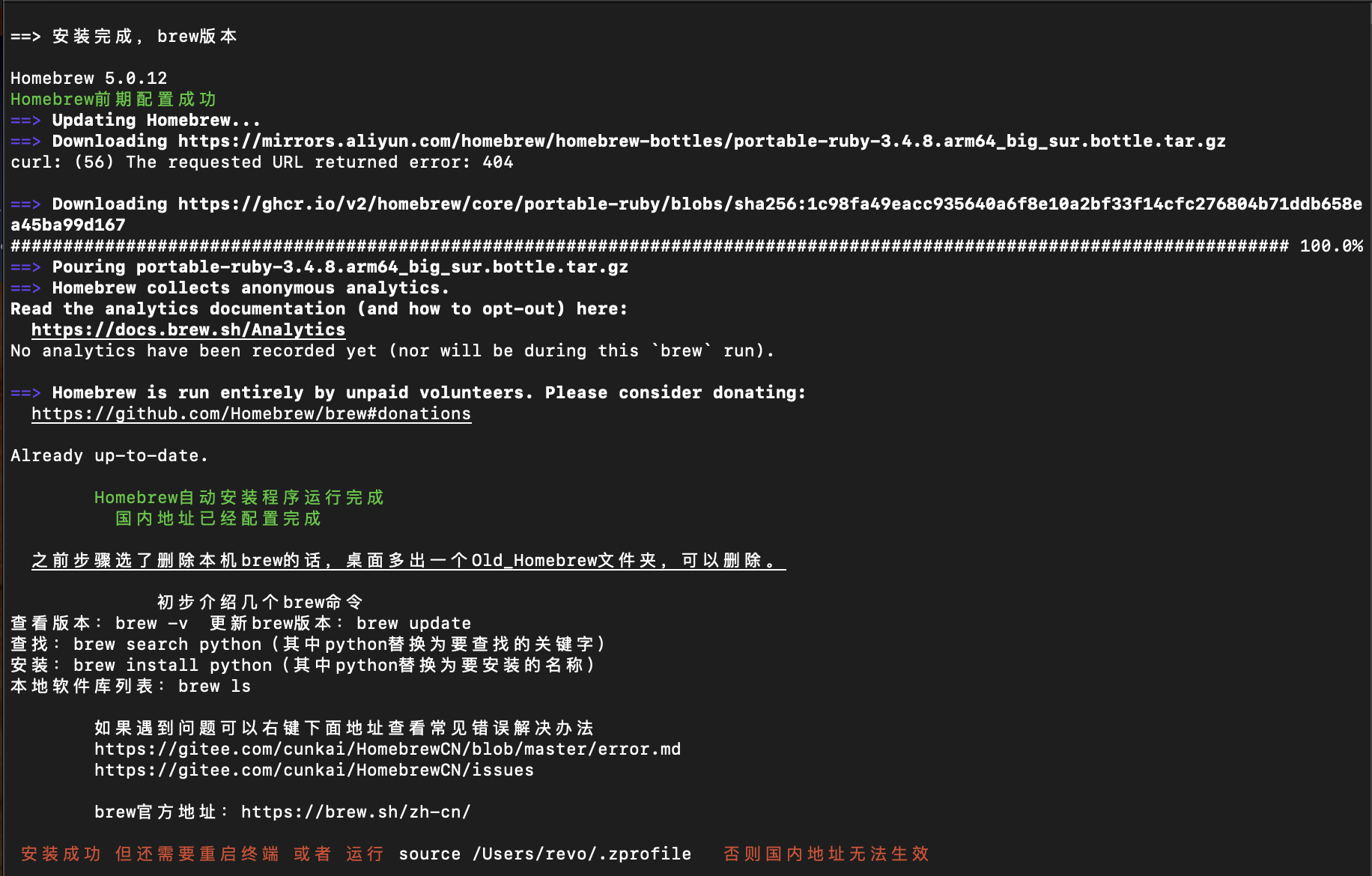
安装 Homebrew(Mac 核心包管理器)
为了绕过网络环境限制,使用了国内维护的安装脚本,并选择了更稳定的镜像源。
执行安装脚本:
/bin/bash -c "$(curl -fsSL ``https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)``"跟着这里的脚本的提示一步一步来就行了
关键配置选择:
- 本体下载源:选择
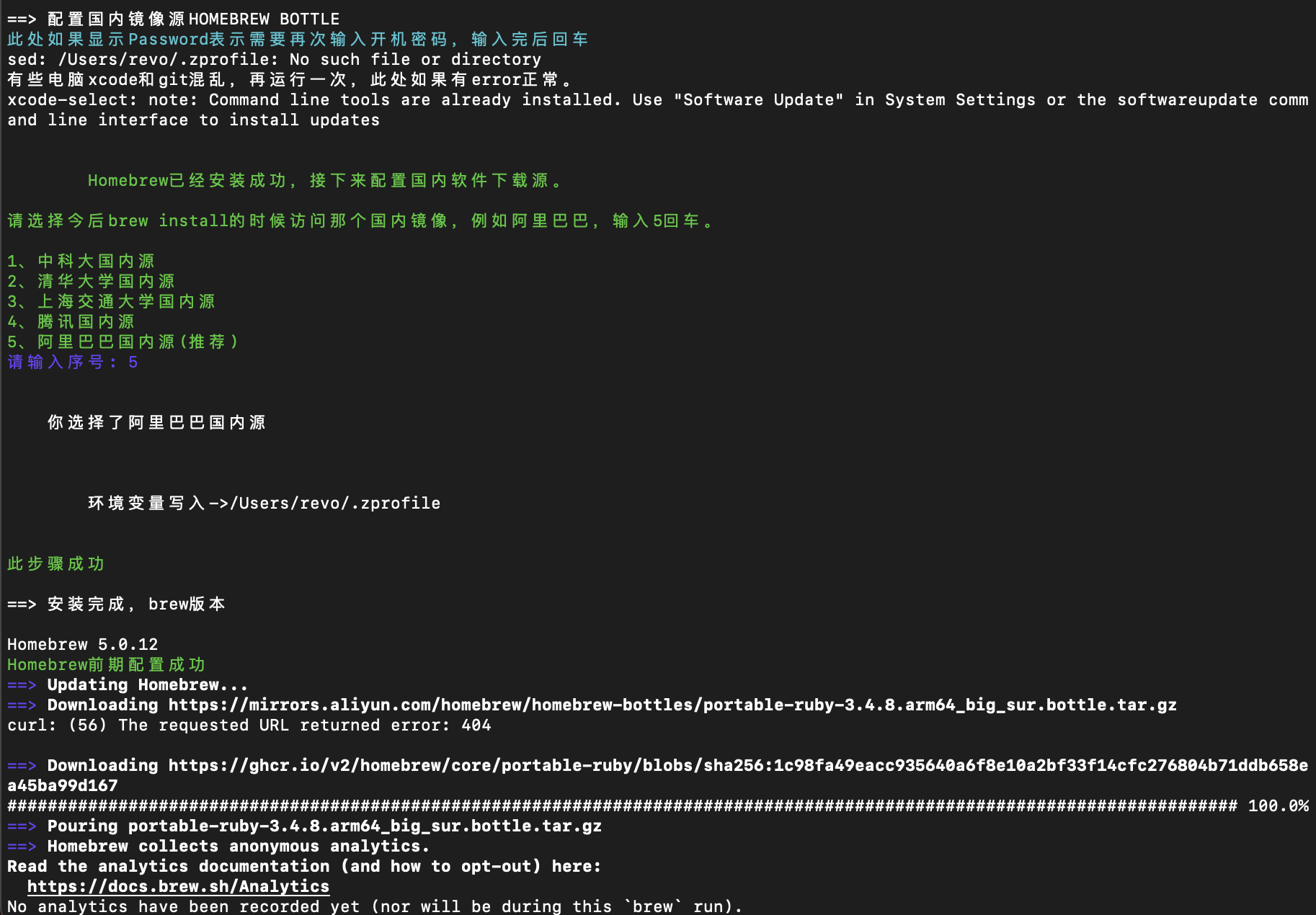
2(Gitee),避开了raw.githubusercontent.com的连接报错。 - 软件镜像源:选择
5(阿里巴巴),确保后续安装软件的速度。
- 本体下载源:选择
激活环境变量:
执行
source ~/.zprofile将brew命令添加到系统搜索路径。验证安装:
brew -v。
全局语言层:Python 3.10(我这边选择的是一个比较稳定的 python 版本)
虽然 macOS 自带 Python,但为了稳定性和后续开发,建议通过 Homebrew 安装一个独立的全局版本。
2.1 安装命令
Bash
brew install python@3.102.2 路径说明
- 安装位置:
/opt/homebrew/bin/python3(可以用 which python3.10 来看在哪) - 用途:用于运行简单的 Python 脚本、安装通用的工具包。
实验室管理层:Miniconda(比较方便一点)
对于 AI、机器学习或复杂项目,Miniconda 是实现“环境隔离”的核心工具。
3.1 安装 Miniconda
Bash
brew install --cask miniconda3.2 初始化与激活
安装后需初始化 Shell,使 conda 命令生效:
Bash
/opt/homebrew/bin/conda init zsh
source ~/.zshrc现象:终端提示符前出现 (base),代表进入了 Conda 基础环境。
3.3 配置国内镜像源 (Conda)
为了加速第三方库的下载,配置清华镜像源:
Bash
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes编辑器配置:VS Code
去 VS Code 官网。正常下载 dmg,然后安装就可以了。
如何开始写代码?(此部分都是跟 windows 那边通用的)
步骤 A:创建独立虚拟环境(这部分建议自己学习一下 conda 环境相关的命令,网上很容易查得到,建议动手试一下)
永远不要在 base 环境下装库。为新项目创建一个新环境:
Bash
conda create -n my_project python=3.10
conda activate my_project步骤 B:在 VS Code 中关联环境
- 在编辑器中打开项目文件夹。
- 按
Cmd + Shift + P-> 输入Python: Select Interpreter。 - 选择你的 Conda 环境(通常会标注为
'my_project': conda)。
维护常用命令速查
配置提示:
- M 系列芯片加速:安装 PyTorch 后,代码中可以使用
device = torch.device("mps")来调用 Mac 的 GPU 进行加速。 - 保持整洁:所有的 Conda 环境现在都规范地保存在
/opt/homebrew/Caskroom/miniconda目录下,不再污染系统路径。
Linux
Python 语法入门
Hello World
在终端直接输入 python 进入终端交互模式:
PS C:\Users\MSforAI> python
Python 3.12.4 (tags/v3.12.4:8e8a4ba, Jun 6 2024, 19:30:16) [MSC v.1940 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>>>> 是输入提示符. 在这后面输入 print("Hello, world!"):
Python 3.12.4 (tags/v3.12.4:8e8a4ba, Jun 6 2024, 19:30:16) [MSC v.1940 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello, world!")
Hello, world!
>>>退出交互模式: 输入
exit(). 即调用退出函数.
不过 Python 肯定不止有这种在终端里输入一行, 解释一行的模式. Python 更常用的是使用脚本.
创建一个后缀为 .py 的文件(Python 源文件的后缀是 .py), 内容为:
print("Hello, world!")Python 不需要什么 main 函数作为程序入口. 程序默认从第一行开始执行. Python 语句之间使用换行符\n 作为分隔, 而不使用分号;进行分隔.
在当前目录下的终端中输入 python xxx.py(xxx 是你的文件名字), 就可以运行.
PS C:\Users\MSforAI\Desktop> python main.py
Hello, world!变量与运算
变量赋值
Python 中变量采用等于号 = 进行赋值, 并且不使用类型声明:
a = 123
var = 0.114514
b = "Hello, MS for AI!"这是因为 Python 是一门"动态类型"语言.
动态类型语言: 程序在运行时才去检查类型. 例如:
pythona = 1 b = "2" c = a + b这个Python程序会报错. 因为
a与b一个是整数类型, 一个是字符串类型, 不能执行+操作. Python在运行程序后, 会在内部隐式自动标注变量的类型, 只有运算的时候出现问题了, 才会报错.
Python中能实现随便修改类型的操作:
var = "114514"
var = 1919810这个操作是允许的. 程序结束前, var 的值最后是 1919810.
Python 中支持多个变量同时赋值, 例如:
a = b = 123
a, b, c = 1, 1.2, "3"变量基本类型
Python 中的变量有这些标准类型:
- 数字 Numbers
- 字符串 String
- 列表 List
- 元组 Tuple
- 字典 Dictionary
- 布尔值 Bool
数字
数字用于存储数. 它们也有以下四种类型:
int有符号整数long长整型,也可以代表八进制和十六进制(python3 后不存在 long, 与 int 类型合并)float浮点数complex复数
a = 1 # int
# python3 中不存在long类型
b = 0.1 # float
c = complex(1, 2) # complex
c = 1 + 2j # complex
c = 1 + 2J # complex#是 Python 的注释标识符. 从#开始直到换行会被视为注释内容, 不会被 Python 解释器运行.
字符串
字符串可以包含大多数字符:
s = "1a_-%$@MSfor AI! 你好, 世界!\n\t"你也可以定义空字符串:
s = ""字符串也可以用单引号定义. 与双引号没区别. 这样可以方便地在字符串中内含":
s = 'abc'
s = '她说: "你是好人, 但是...你没有学过MS for AI. 抱歉!"'定义很大的字符串, 可以使用 3 个双引号:
s = """Missing Semester for AI
copyright@131AIClub
人工智能教育中缺失的一课
这是一个很大大大大大大大的字符串...
没有了
"""注意, """也可以用于大规模注释:
python
""" 这是一个很大大大的注释 一般会用于编写文档. """
"""这也是注释, 换不换行并不会影响"""
字符串的一个很重要的操作是**切片**. 切片使用中括号来标记一个下标区间, 左闭右开:
```python
"""
特别要注意:
1. 索引从0开始.
2. 切片的右边值无法取到. (左闭右开)
"""
s = 'Missing Semester for AI'
print(s[0: 7]) # Missing
print(s[8: 16]) # Semester
print(s[0: 2]) # Mi字符串切片还可以有第三个值, 含义是"步长", 即取数每一步的长度. 默认为 1, 即区间内全取. 步长也可以取负数.
s = 'Missing Semester for AI'
print(s[0: 7: 2]) # Msig
print(s[8: 16: 3]) # See切片的三个值都是可以不输入的. 默认值分别为:
- 第一个值(起始位置): 0, 即串的开头.
- 第二个值(结束位置): len(s), 即串的长度.
- 第三个值(步长): 1, 即全取.
len函数: 返回串的长度:python
s = "012345" length = len(s) # 6
例如:
```python
s = 'Missing Semester for AI'
print(s[::]) # Missing Semester for AI
print(s[:: -1]) # IA rof retsemeS gnissiM
print(s[2:]) # ssing Semester for AI
print(s[: 3:]) # Mis列表
List(列表) 是 Python 中使用最频繁的数据类型.
列表可以完成大多数集合类的数据结构实现. 它支持数字, 字符串甚至可以包含列表(即嵌套).
准确来说, 列表几乎可以装任何对象. 并且不要求列表元素是同一个类型.
l = [1, "2", [3, 4]]
l = [] # 空列表
l = list() # 这个也是空列表列表是动态长度的, 可以通过 append 方法来添加新元素:
l = []
l.append("I")
l.append("love")
l.append(['MSforAI', '!'])
print(l) # ['I', 'love', ['MSforAI', '!']]列表删除元素可以使用 pop 和 remove 方法.
pop方法接收一个参数作为要删除的元素的索引. 缺省值为-1, 即最后一个元素.pop方法会返回删除的元素:
l = [1, 2, 3]
pop_value = l.pop()
print(l) # [1, 2]
print(pop_value) # 3
l = [1, 2, 3]
pop_value = l.pop(1)
print(l) # [1, 3]
print(pop_value) # 2remove方法接收一个匹配值, 会删除第一个匹配到的元素.remove没有返回值(返回None):
l = [1, 2, 'MSforAI', '天天天国地狱国']
remove_value = l.remove('MSforAI')
print(remove_value) # None
print(l) # [1, 2, '天天天国地狱国']列表可以使用索引访问和修改元素:
l = [1, 2, 3]
print(l[1]) # 2
l[0] = 'new'
print(l) # ['new', 2, 3]列表支持切片操作. 逻辑与字符串基本相同:
l = [0, 1, 2, 3, 4, 5]
s = l[::-1] # [5, 4, 3, 2, 1, 0]
s = l[:2] # [0, 1]元组
在当前阶段, 你可以认为元组与列表最大的区别就是: 元组是不可变的.
定义元组使用括号():
t = (1, 'it', 'is a tuple!')
t = (,) # 空元组
t = tuple() # 空元组为什么
t=(,)要加逗号? 这是因为, 如果你写()会出现歧义: 为什么()不是个空表达式? 虽然 Python 解释器确实会认为()是个空元组, 但是为了避免歧义, 最好写个逗号. 实际上, 你在定义只有一个元素的元组时, 必须要写个逗号:python
t = (1,)
> 如果你不写逗号, Python解释器会认为这是个表达式, 最终`t`的类型是`int`
> ```python
t = (1)
print(type(t)) # <class 'int'>你可以通过索引来读取元组中的值, 但是你不能修改(准确来说, 是你不能更换元组中的对象):
t = (1, 2, 3)
print(t[2]) # 3
t[0] = 123 # 这行会报错
t = (1, 2, [1, 2])
t[2].append(3) # 可以!
print(t)这里列表可以被更新是因为, 你没有更换元组中的对象, 列表还是那个列表, 只是列表自己的内含值变了.
由于元组不能修改, 所以元组是定长的.
元组也支持切片操作, 逻辑类似字符串:
t = (1, 2, 3, 4, 5)
print(t[:3]) # (1, 2, 3)字典
字典是无序的对象集合. 由键值对组成. 你可以通过键 key 来快速查找到值 value.
字典在实现上使用哈希表(散列表).
字典使用花括号{}定义, 使用引号:来分隔键值对:
d = {1: '1', 2: '4', 3: 'AI', 4: 'vibe'}
d = {} # 空字典
d = dict() # 空字典字典的值可以是绝大多数的 Python 对象. 但是字典的键必须是可哈希的. 列表与元组是不可哈希的, 因此不能作为字典的键.
Python 判断是否可哈希, 是通过该对象是否实现
__hash__魔术方法来判断的. 这部分的内容, 有兴趣的同学可以自己查询资料来学习. 在后续学习了面向对象后, 大家对这一块会有更清楚的认识.
d = {
(1, 2, 3): 654 # 报错!
}字典可以通过键(key)来查找值(value):
d = {
1: "i",
2: "love",
"3": 131,
114514: ['c', 'l', 'u', 'b'], # 最后一个键值对的逗号,可省略
}
print(d[1]) # i
print(d['3']) # love
print(d[114514]) # ['c', 'l', 'u', 'b']字典添加键值对最常用以下两种方式:
- 直接赋值
update方法
直接赋值的形式如下:
d = {}
d['key1'] = 'value1'
d['key2'] = 'value2'
d[131] = ('ai', 'club')
print(d) # {'key1': 'value1', 'key2': 'value2', 131: ('ai', 'club')}update 方法形式如下:
d = {}
# 第一种update使用方法
d.update({1: "131", '2': 666})
d.update({5: '222'})
# 也可以使用参数式定义, 参数名会被转为string类型键
d.update(club=131)
d.update(roxy='wife', msforai='love')
print(d) # {1: '131', '2': 666, 5: '222', 'club': 131, 'roxy': 'wife', 'msforai': 'love'}删除字典的键, 可以使用 del 语句, 或者 pop 方法.
更常用的是 pop 方法, pop 方法会返回删除值:
d = {'club': 131, 'ms': ['y', 'e', 's'], 'key': 100}
value = d.pop('ms')
print(value) # ['y', 'e', 's']
print(d) # {'club': 131, 'key': 100}del 语句的形式:
d = {'club': 131, 'ms': ['y', 'e', 's'], 'key': 100}
del d['ms']
print(d) # {'club': 131, 'key': 100}
del语句还有更多的用处. 这里限于课程性质, 不介绍. 想要学习的同学可以查找相关资料来学习. C++ 中 delete 语句很重要, 而在 Python 中del语句却没那么重要. 这是因为 Python 中有垃圾回收机制.** **Python 解释器维护了一个垃圾收集器(Garbage Collector, GC), 它会按照一个规则(通常是引用计数)来回收用户不使用的对象. 因此 Python 程序员一般情况下不需要考虑回收问题.
布尔值
Python 中的布尔值类似数字型变量. 其只有两种值: True 和 False:
# 布尔值要大写: 是True和False, 不是true和false.
t = True
f = False基本运算
数字型变量加减乘除
一些大家肯定懂的东西, 这里就快速介绍.
数字型之间的加减乘除是很符合直觉的:
"""
int与float之间运算, 不需要显式类型转换, 会默认全转成float.
"""
# 加
a = 1
b = 0.1
print(a + b) # 1.1
# 减
a = 1
b = 3.1
print(a - b) # -2.1
# 乘
a = 1.1
b = 2
print(a * b) # 2.2
# 除
a = 1
b = 3
print(a / b) # 0.3333333333333333
# 整除
a = 7
b = 3
print(a // b) # 2
# 取余(模)
a = 7
b = 3
print(a % b) # 1复合运算符, 即 +=, -= 等, Python 也是支持的:
a = 1
a += 1
print(a) # 2
a -= 5
print(a) # -3
a /= 2
print(a) # -1.5
... # 你没看错, ...真的是个Python关键字, 与pass差不多接下来介绍一些特殊的运算:
字符串加法与乘法
字符串的加法实际就是拼接:
s1 = 'Hello, '
s2 = 'world!'
print(s1 + s2) # Hello, world!
s = '131' + 'AI' + 'Club'
print(s) # 131AIClub字符串乘法就是重复拼接:
s = '131' * 3
print(s) # 131131131列表加法与乘法
列表加法与乘法与字符串类似:
l1 = [1, 2, 3]
l2 = ['1', '2', '3']
l = l1 + l2
print(l) # (1, 2, 3, '1', '2', '3')
l = [1, 3, 1] * 3
print(l) # (1, 3, 1, 1, 3, 1, 1, 3, 1)元组的加法与乘法
与列表, 字符串基本相同:
t1 = (1, 2, 3)
t2 = ('1', '2', '3')
t = t1 + t2
print(t) # [1, 2, 3, '1', '2', '3']
t = [1, 3, 1] * 3
print(t) # [1, 3, 1, 1, 3, 1, 1, 3, 1]字典的合并运算 |
字典的合并运算 | 是在 Python3.9 引入的. 它可以合并两个字典:
d1 = {1: '1', 2: '2'}
d2 = {'1': 1, '2': 2}
d = d1 | d2
print(d) # {1: '1', 2: '2', '1': 1, '2': 2}分支与循环
程序的基本控制结构就是顺序, 分支, 循环. Python 作为健全的语言, 肯定是可以实现这些基本的控制结构.
分支
if-else
Python 实现分支需要使用 if 与 else 关键字:
if True:
a = 1
else:
a = 2
print(a) # 1注意程序缩进: 分支的语句体需要向内缩进一个单位(一般是 4 个空格)
多分支可以使用 else if:
flag = 5
if flag > 10:
print('flag > 10')
else if flag > 5:
print('flag > 5')
else if flag > 0:
print('flag > 0')
else:
print('flag <= 0')
# flag > 0注意, 在多分支结构中, 遇到了一个匹配项, 则后续全部分支都会跳过.
match-case
Python3.10 引入的新语法, 对标 switch 语法.
status = 3
match status:
case 1:
print('情况1')
case 2:
print('情况2')
case 3:
print('情况3')
case _:
print('未知情况')留个印象就可以了, 很少用.
循环
循环主要由两种关键字实现, 分别是 while 和 for.
While
while 关键字后面需要写一个布尔值表达式, 代表循环继续条件. 循环会一直进行到条件不满足为止:
i = 0
while i < 10:
print(i)
i += 1
# 这是一个死循环
while True:
pass如果想要中途直接退出循环(而不是等待循环条件不满足), 可以使用 break 语句:
# 这个循环只会输出到6
i = 0
while i < 10:
print(i)
if i > 5:
break
i += 1还有一个语句是 continue. 它会直接开始下一次循环, 跳过 continue 后面执行的语句:
i = 0
while i < 131:
print(i)
continue # 这里会导致死循环!
i += 1while-else 语句. 实际上 while 还有一个 else 语句, 不过大多数情况下我们是不使用的. 它的含义就是在 while 循环结束后, 执行 else 语句中的内容. 但是注意: 通过 break 退出的循环, 不会执行 else 的内容.
i = 0
while i < 10:
print(i)
i += 1
else:
print('loop1 finish!')
i = 0
while i < 10:
print(i)
if i > 5:
break
i += 1
else:
print("loop2 finish!")
# 你只会看到loop1 finish!For
for 比 while 用的会更多一些(我的身边统计学). for 循环需要指定循环变量与迭代器. range() 函数会生成一个迭代器. 它接收整数作为输入, 返回一个按照一定规则迭代整数的迭代器. 列表与元组也是可迭代的, 会依次按顺序迭代出其内含的元素.
for i in range(10):
print(i)
l = [131, 'ai', 'club', 'ms', 'for', 'ai']
for item in l:
print(item)
t = ('it', 'is', 'a', 'tuple')
for item in t:
print(item)循环变量有时候我们是不关心的, 即在循环中我们不会使用. 例如说, 我们只是希望一个相同的过程执行 100 次, 但是我们并不需要知道我们执行到第几次. 而且, 最关键的是, 我们懒得想变量名. 这个时候, 你可以用占位符来替代变量标识符:
for _ in range(100):
print("I don't care i.")除了替换循环变量标识符, 占位符也可以替换变量赋值的位置:
t = ('131AIClub', 'MSforAI', 114514)
name, coure, _ = t # 我不关心最后一个值, 而且我懒得想变量名在终端交互环境中, 占位符 _ 可以用于指代最近的一个表达式的值:
Python 3.12.4 (tags/v3.12.4:8e8a4ba, Jun 6 2024, 19:30:16) [MSC v.1940 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> 12.44*5 + 0.22
62.419999999999995
>>> a = 10
>>> _
62.419999999999995
>>>有关迭代器的更多讲解, 介于课程性质, 不介绍. 感兴趣的同学可以自己查阅资料学习.
函数
Python 使用 def 关键字声明函数. 分别需要声明: 函数标识符(函数名), 函数参数(arguments). 并使用 return 语句来声明返回值. 如果没有声明返回值, 则返回 None.
def func(x, y):
z = x + y
return z
def foo():
pass通过函数标识符 +()来调用函数:
def func(x, y):
return x + y
print(func(1, 2)) # 3
print(func(x=1, 2)) # 报错! 关键字指定要在最后
print(func(1, y=2)) # 3
print(func(x=1, y=2)) # 3调用函数时, 不写参数名的是位置参数, 写参数名的是关键字参数.
递归
Python 是支持递归的, 例如下面这个计算 Fibonacci 数的程序:
def fibonacci(n: int) -> int:
if n <= 2: return 1
return fibonacci(n-1) + fibonacci(n-2)
for i in range(1, 11):
print(fibonacci(i), end=' ')Python 类型注释. Python 虽然不需要声明变量类型, 但是你也可以通过类型注释来声明变量类型. 类型注释在运行时不会有任何影响, 但是在编写程序时的 lsp 分析中很有用: lsp 可以进行类型推导, 提前发现一些类型错误. 类型注释的基本方法是在变量的后面加
:<类型>, 例如x: int,s: str. 函数返回值的类型注释可以通过在函数声明行添加-><类型>来实现, 例如def f() -> None:,def g(x: int) -> str:
闭包
闭包. Python 函数的参数与返回值可以是函数!
"""
这是一种叫做"装饰器"的Python编程技巧.
@是一个语法糖:
例如@func1, 就是把后面第一个定义的函数, 作为参数传入func1中, 并使用func1的返回值替换这个定义的函数.
"""
from typing import Callable, ParamSpec, TypeVar
P = ParamSpec('Params')
R = TypeVar('Return')
def dec(f: Callable[P, R]) -> Callable[P, R]:
def g(*args: P.args, **kwargs: P.kwargs) -> R:
print(f.__name__ + " 执行!")
return f(*args, **kwargs)
return g
@dec
def add(x: int, y: int) -> int:
return x + y
print(add(1, 2))可变参数
*args与**kwargs:*args用于接收任意数量的位置参数,这些参数会被收集到一个元组中. 而**kwargs用于接收任意数量的关键字参数, 会被收集进一个字典中.
闭包的实际定义其实比较复杂, 并不是简单的"参数与返回值可以是函数". 这一块内容其实不能算是 Python 入门了...
大家只要有这个思想就可以了, 知道 Python 中函数是一个比较灵活的东西, 实际上只是一个 Callable, 可调用的东西.
面向对象
Python 是一门面向对象的语言. 尽管一直有人在抨击 OOP(面向对象英文简写)模式, 但是面向对象确实是利于人类程序员建模现实问题, 组织程序结构. 不管你有没有对象, 你都得先想办法面向对象. 每当我写一个新项目时, 第一个写的总是继承抽象类的类, 不管有没有必要写这个类. 但是, 最佳实践这一块 hhh.
简单回顾一下面向对象的一些基本概念. 类是对象的蓝图或模板, 对象是类的实例. 类定义了对象的属性和行为. 我们把一些事物分类进一个类中, 并且抽象出一些共同属性, 就构成了类.
例如说, 我想要编写一个服务器后端, 它的功能是接收用户请求, 返回用户需要的图片(一个很常见的例子是图床, 虽然那个是随机的). 我其实可以选择为用户请求实现一个类, 每当接收一个用户请求, 我就实例化一个用户请求对象. 而用户请求类内部包含请求的用户名, 请求的图片 id, 请求的优先等级等属性, 这些属性是共通的. 如果我不适用类来实现, 那这将变得很麻烦, 我不得不维护很多的变量, 没有办法把这些属性组织起来.
Python 中定义类使用 class 关键字:
class A:
...
a = A() # 实例化一个对象不过现在这个类啥都没实现...
一般来说首先要实现的是构造函数. Python 中规定了类的构造函数为 __init__ 魔术方法:
class Car:
def __init__(self, color: str) -> None:
self.color = color
def print_color(self) -> None:
print(f'My color is {self.color}!')
car = Car('red')
car.print_color()
print(car.color)self 不需要外部提供, 代表对象本身. 这个参数是不能放在中间, 只能放在第一个的. 如果没有 self 参数, 该方法被称为静态方法(static method). 静态方法需要 staticmethod 装饰器才能实现.
继承与多态
Python 类当然是支持继承与多态的.
类的继承形式如下:
class Animal:
def __init__(self, name: str) -> None:
self.name = name
def move(self) -> str:
return f'{self.name} is moving!'
def speak(self) -> str:
return "Some sound..."
class Dog(Animal):
def speak(self):
return f'{self.name} says Woooof!'
dog = Dog('puppy')
print(dog.speak())类可以多层继承, 也可以多重继承:
class Machine:
def work(self) -> str:
return 'Machine is working...'
class Vehicle(Machine):
def work(self) -> str:
return 'Vehicle is working...'
class Car(Vehicle): # 多层继承
def work(self) -> str:
return 'Car is working...'
class Flyable:
def fly(self) -> str:
return 'Something is flying...'
class Plane(Vehicle, Flyable): # 多重继承
def fly(self) -> str:
return 'Plane is flying...'
car = Car()
print(car.work())
plane = Plane()
print(plane.fly())
print(plane.work())Python 的类默认继承 object:
class A(object):
...
class A: # 等价
...如果你想在子类中扩展而非完全替换父类的方法, 你可以使用 super() 函数. super() 将返回一个类似父类对象的东西:
class Animal(object):
def __init__(self, name: str) -> None:
self.name = name
class Dog(Animal):
def __init__(self, name: str, age: int) -> None:
super().__init__(name)
self.age = age
dog = Dog('dog_name', 114514)
print(dog.name, dog.age)多态即同一个接口由多个不同类型使用, 实现不同的功能. 例如:
import math
class Shape:
def area(self) -> float:
raise NotImplementedError()
class Triangle(Shape):
def __init__(self, a: float, b: float, c: float) -> None:
self.a, self.b, self.c = a, b, c
def area(self) -> float:
a, b, c = self.a, self.b, self.c
p: float = 0.5 * (a + b + c)
return math.sqrt(p * (p - a) * (p - b) * (p - c))
class Circle(Shape):
def __init__(self, r: float) -> None:
self.r = r
def area(self) -> float:
r = self.r
return math.pi * r ** 2
class Square(Shape):
def __init__(self, h: float, w: float) -> None:
self.h, self.w = h, w
def area(self) -> float:
h, w = self.h, self.w
return h * w
triangle = Triangle(3, 4, 5)
circle = Circle(1.5)
square = Square(2, 4)
print(triangle.area())
print(circle.area())
print(square.area())这里都继承了 area 接口, 但每个子类有自己的实现. 以此来实现多态.
类型检查
Python 可以使用 isinstance 与 issubclass 进行类型检查:
x: int = 1
print(isinstance(x, int)) # True
class A: pass
a: A = A()
print(isinstance(a, A)) # True
y: float = 0.
print(isinstance(y, int)) # False
print(isinstance(y, (int, float))) # True, 多类型判断issubclass 用于检查一个类是否属于某个类的子类:
class Animal: pass
class Dog(Animal): pass
print(issubclass(Animal, Dog)) # False
print(issubclass(Dog, Animal)) # TruePython 包管理
技术的本质就是调包~~! ~~
「复用」是软件工程中一个十分重要的概念。如果我们想要实现的功能在项目的其他地方已经存在,那么我们就不必再次实现它。我们可以将程序的各个部分共享的逻辑提取出来,这样一来既可以避免代码的冗余,修改时也可以仅在一处修改,而不是在所有相同逻辑出现的地方进行修改。许多编程语言为了支持这样的复用都发展出了相应的机制,例如函数允许实现对于过程的复用,而语言中的类和对象和相关的 OOP 机制允许实现更加复杂的,对于数据结构和过程的复用。
然而,以上所说的这些复用机制仅仅局限于单个项目内。实际开发中,我们经常需要跨项目或跨团队共享和复用已有的功能。这就引出了「跨项目复用」的概念。我们可以把共同的逻辑提取出来,让这些逻辑本身成为一个单独的项目进行维护。在今天,你已经知道,这样的项目叫做「库」。今天的数字基础设施正是由一个又一个或大或小的「库」组成。得益于计算机科学的发展和自由软件运动,我们在今天可以轻而易举地获取到别人发布的开源库,并用在自己的项目中。这样一来,复用的规模被再一次扩大了,它并非局限于某个组织、国家或地区,而是所有人类程序员之间的复用。(为什么一定要是人类?)

[自行查阅 python 中的模块与包]
在前面的课程中,你已经使用过一些库了。它们通过 import xxx 的形式被导入,在那之后你就可以使用他们。但是到此为止,你使用的都是 python 自带的标准库。想要使用其他的库,你需要使用包管理器。python 官方提供了一个称为 pip 的包管理器,它随着 python 解释器的本体安装。想要使用它,只需要运行 pip:
$ pip
Usage:
pip <command> [options]
Commands:
install Install packages.
download Download packages.
uninstall Uninstall packages.
freeze Output installed packages in requirements format.
list List installed packages.
show Show information about installed packages.
check Verify installed packages have compatible dependencies.
config Manage local and global configuration.
search Search PyPI for packages.
cache Inspect and manage pip's wheel cache.
index Inspect information available from package indexes.
wheel Build wheels from your requirements.
hash Compute hashes of package archives.
completion A helper command used for command completion.
debug Show information useful for debugging.
help Show help for commands.
General Options:
-h, --help Show help.
--isolated Run pip in an isolated mode, ignoring environment variables and user configuration.
-v, --verbose Give more output. Option is additive, and can be used up to 3 times.
-V, --version Show version and exit.
-q, --quiet Give less output. Option is additive, and can be used up to 3 times (corresponding to
WARNING, ERROR, and CRITICAL logging levels).
--log <path> Path to a verbose appending log.
--no-input Disable prompting for input.
--proxy <proxy> Specify a proxy in the form [user:passwd@]proxy.server:port.
--retries <retries> Maximum number of retries each connection should attempt (default 5 times).
--timeout <sec> Set the socket timeout (default 15 seconds).
--exists-action <action> Default action when a path already exists: (s)witch, (i)gnore, (w)ipe, (b)ackup,
(a)bort.
--trusted-host <hostname> Mark this host or host:port pair as trusted, even though it does not have valid or any
HTTPS.
--cert <path> Path to PEM-encoded CA certificate bundle. If provided, overrides the default. See 'SSL
Certificate Verification' in pip documentation for more information.
--client-cert <path> Path to SSL client certificate, a single file containing the private key and the
certificate in PEM format.
--cache-dir <dir> Store the cache data in <dir>.
--no-cache-dir Disable the cache.
--disable-pip-version-check
Don't periodically check PyPI to determine whether a new version of pip is available for
download. Implied with --no-index.
--no-color Suppress colored output.
--no-python-version-warning
Silence deprecation warnings for upcoming unsupported Pythons.
--use-feature <feature> Enable new functionality, that may be backward incompatible.
--use-deprecated <feature> Enable deprecated functionality, that will be removed in the future.pip 提供了很多命令和可用的选项。在所有这些选项当中,我们最常用的是 pip install。在后面加上你想要安装的库的名字,pip 就会自动帮你安装这个库。有的库还依赖其他的一些库,pip 会自动寻找合适的版本,并且安装它们。但是在那之前,你需要先配置清华镜像源。在你执行下面这行命令之后,pip 会默认到清华 PyPI 镜像下载包,而不是缓慢的官方源。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple在这之后,你就可以自由地使用 pip 了。你可以安装 numpy 库,这是一个高性能计算库,我们会在下一节用到它。
pip install numpy你可以尝试
import numpy如果没有报错,那么恭喜你,已经成功安装了自己的第一个包!
虚拟环境
尝试在你的机器上执行下面这段 python 代码:
import sys
print(sys.path)你得到了一个路径列表。许多时候我们认为 python 的包管理机制是神秘的,但是它的原理实际上相当简单。当你运行 import xxx 的时候,python 解释器会在 sys.path 包含的这些路径里寻找你要的那个包,如果没有,那就报错。路径列表中往往会包含类似 ...\\python\\lib\\site-packages 这样的路径,这正是 pip 默认的库安装位置。打开这个路径,你会找到一个名为 numpy 的文件夹,刚刚运行的 pip install numpy,正是把 numpy 放到了这里。
默认情况下,Python 采用的是全局包管理模式。无论你在电脑的哪个角落打开终端运行 pip install,Python 的 sys.path 都会是一样的。当你只有一个项目时,这看起来很方便。但你很快就会遇到这种尴尬的场景:如果你正在做两个项目,项目 A 需要 numpy==0.1,而项目 B 需要 numpy==0.3,由于 site-packages 文件夹在同一个 Python 安装目录下只有一份,后安装的版本会直接覆盖掉前者,而更新版本的包很可能不支持旧版本的一些功能,导致项目 A 没法再跑起来。
一个更加合理的方式是,把每个项目自己依赖的包分别管理起来。我们希望能够创建一些相互隔离的场所,这样不同的项目之间就不会相互影响,这样的技术被叫做虚拟环境。
python -m venv .venv这条命令的意思是:调用 venv 模块,在当前目录下创建一个名为 .venv 的文件夹。创建了文件夹还不算完,我们必须「激活」这个环境。
.venv\Scripts\activate此时,命令提示符前面出现了一个 (.venv),这说明你已经在 .venv 这个虚拟环境下了。再次尝试
>>> import numpy
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'numpy'你可以看到,之前安装的 numpy 已经没有了,这是一个隔离于外界的,不受干扰的环境。
有了前面的铺垫,你其实应该能猜出这是怎么实现的——只需要修改 sys.path 就好了!再次查看 sys.path:
import sys
print(sys.path)你会发现,sys.path 里面的 site-packages 已经不再是那个全局的 site-packages,而是被指向了 .venv 这个文件夹里的 site-packages。此时运行
where.exe pip你会发现,系统默认搜寻到的 pip 也变成了 .venv\Scripts 下面的这个 venv 自己独特的 pip,它会把包安装到虚拟环境的 site-packages 里面,而不是全局的 site-packages。
Conda
在 AI 领域,很多包(如 PyTorch, TensorFlow)不仅包含 Python 代码,还深度依赖 C++ 库、CUDA 驱动等。venv 管不到这些非 Python 的二进制文件。我们需要比 venv 更加强大的虚拟环境管理。
Conda 管理的是整个运行环境,包括 Python 解释器本身、CUDA 工具链、C++ 编译器等。Conda 的环境通常是全局集中管理的。它会在你的电脑某个角落(如 ~/miniconda3/envs/)开辟一个完整的隔离区。如果说 venv 靠的是修改 sys.path 这个 python 的包搜索路径,那么 Conda 更进一步,它还会修改 PATH 这样系统级的搜索路径。
Conda 是一个包管理的引擎,本体其实只有几十 MB 而已,有人围绕着它加入了各种预装的包,然后全部放在一起安装,形成了各种发行版。其中最有名,应用得也最广泛的是 Anaconda,它预装了 NumPy、Pandas、Matplotlib、Scikit-learn 等几乎所有数据科学必备的库,还提供了 Anaconda Navigator 这种图形界面,让你不用敲命令就能管理环境。在 Windows 上,很多 Python 库(比如带有 C++ 扩展的库)直接用 pip 装经常报错,Anaconda 预编译好了二进制文件,保证能在 Windows 上跑通。理所当然地,Anaconda 安装完的体积膨胀到了 3~5GB。
相比之下,Miniconda 提供了一个最小化的 conda 发行版,体积只有大概 300-500M,它足以满足几乎所有的日常使用。你可以到这里下载 Miniconda:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/。
安装完成之后,直接打开终端并输入 conda:
conda如果你是在 windows 上使用 conda,那么很遗憾,这个命令因为找不到 conda 而报错了。conda 的机制主要是通过管理环境变量来实现的,而 Windows 的环境变量管理和 Linux 不太一样,出于隔离环境变量的要求(你也不想 conda 环境里的环境变量搞坏了外面的东西),想要运行 conda,你要使用一个单独的命令提示符:
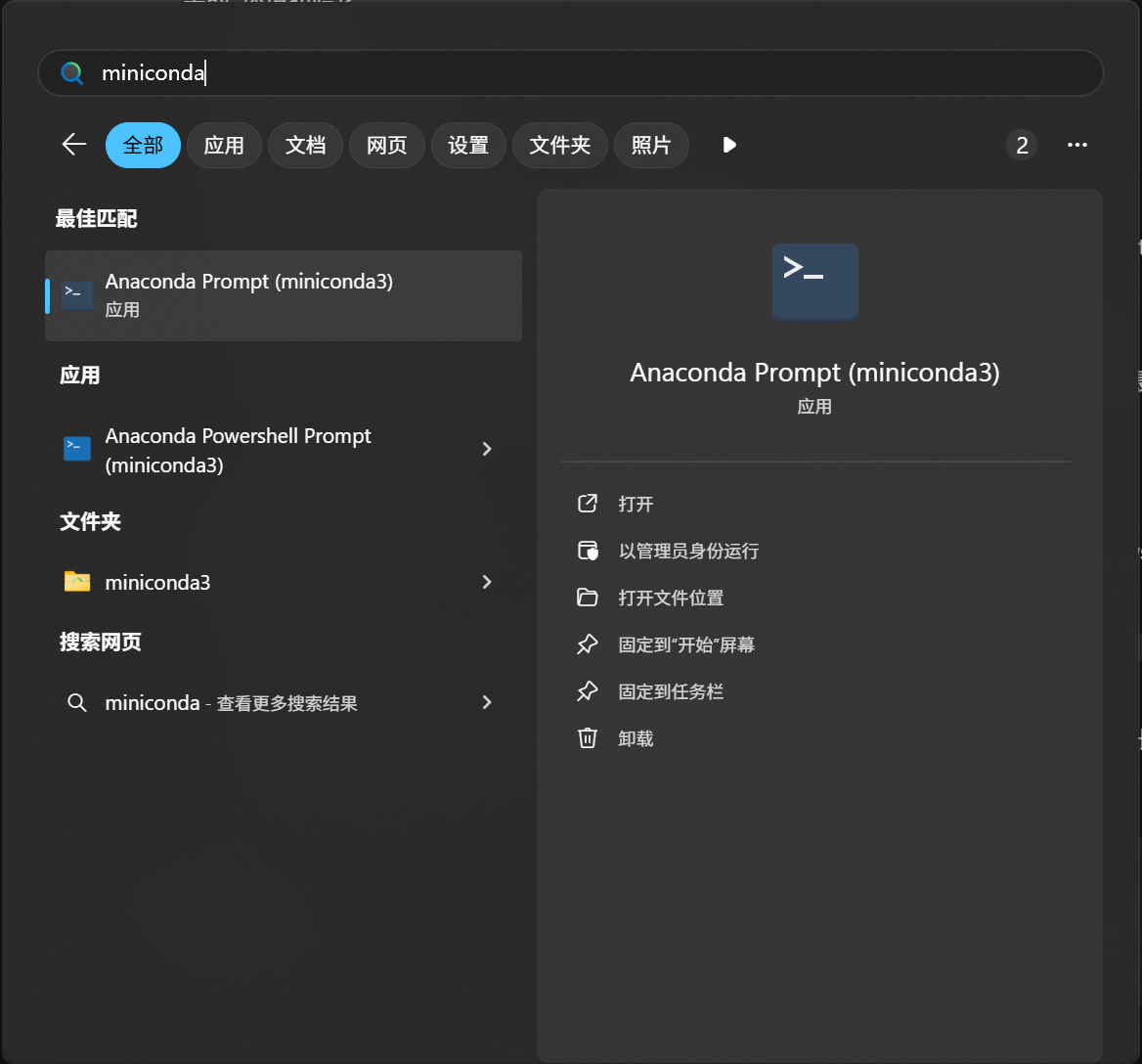
如果你查看这个文件的内容,会发现它是一个非常简单的快捷方式:
%windir%\System32\cmd.exe "/K" D:\miniconda3\Scripts\activate.bat D:\miniconda3先打开一个普通的 Windows 命令行,然后在里面运行 activate.bat 这个脚本。
总而言之,打开这个特殊的命令行,你会发现提示符变了样子,前面多了一个 (base)。这指示了你当前所处的 conda 环境的名字。对于 conda 而言,默认会创建一个环境,它的名字就叫做 base。
(base) C:\Users\XXX>base 相对于其他环境的特殊点在于,conda 本体就安装在 base 环境。所以为了不搞出什么依赖冲突导致 conda 命令无法运行,通常情况下我们都会在自己建立的新环境里进行操作。
了解了这些之后,你就可以开始尝试使用 conda 了。以下是 conda 常用命令的列表:
查询环境列表:conda env list 或 conda info --envs。 它会列出你电脑上所有的工作区路径,当前激活的环境前面会标有一个星号。
创建新环境:conda create -n <环境名> python=3.10。建议养成在创建时显式指定 python 版本的习惯。如果不指定,Conda 可能会默认给一个不符合你项目要求的版本。
激活与退出:
- 进入环境:
conda activate <环境名> - 回到 base 环境:
conda deactivate
克隆环境:conda create -n <新名字> --clone <旧名字>。
删除环境:conda remove -n <环境名> --all。
在激活了特定环境后,你就可以开始安装工具了。
安装包:conda install <包名>。 如果需要特定版本,可以使用 conda install <包名>=1.2.3。Conda 会自动帮你分析依赖冲突。
更新与卸载:
- 更新:
conda update <包名> - 卸载:
conda remove <包名>
导出与复现:当你完成了一个项目,需要把它交给同学时,使用: conda env export > environment.yml 对方只需要运行 conda env create -f environment.yml,就能还原一个一模一样的环境。
uv
uv 是一个使用 rust 编写的 python 包管理器。它的一大特点是快。在上一节里我们介绍了 conda,如果你尝试过使用 conda 安装包,你应该体会过 conda 在解析包依赖的这个阶段运行得十分缓慢。得益于 Rust 的底层性能,uv 的依赖解析和安装速度通常比传统工具快数十倍甚至上百倍。
同时,uv 借鉴了 Rust 的 Cargo 和前端工具的设计,原生支持基于 pyproject.toml 的工作流。以往在 conda 当中,我们往往需要导出 environment.yml,而在 uv 的包管理模式中,所有的依赖和它们的版本要求都被清晰地写入 pyproject.toml。在 pyproject.toml 中,我们通常只声明项目的顶层依赖和较为宽泛的版本要求。而 uv 在解析这些依赖后,会生成一个极其严谨的 uv.lock 锁文件。这个文件记录了整个依赖树中每一个包的精确版本号甚至哈希值。只要基于同一个锁文件构建环境,安装的依赖分支将完全一致,这就从根本上保证了项目依赖的可复现性。
在传统的 pip 或 conda 工作流中,如果你在十个不同的项目里都用到了同一个版本的重型依赖,比如 PyTorch 或是 Transformers,你的硬盘上就会真的存下十份一模一样的庞大文件。而 uv 彻底改变了这一点。当你第一次下载某个包时,uv 会把它存放在系统的全局缓存目录中。之后无论你在多少个新的虚拟环境或是项目中需要安装这个特定版本的包,uv 会直接利用操作系统的硬链接机制,将虚拟环境中的包指向全局缓存里的同一份文件,如果你熟悉一些前端工具,你会发现这和 pnpm 是非常类似的。
由于 uv 是一个用 Rust 编译出的独立二进制文件,它的安装和运行完全不需要依赖系统中现有的 Python 环境。
在 Linux 或 macOS 系统中,你可以直接通过终端一键安装:
curl -LsSf https://astral.sh/uv/install.sh | sh如果你使用 windows,也可以:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"安装完成后,我们可以体验一下现代化的项目构建流程。假设你需要新建一个研究项目,只需在目标目录下执行:
uv init my-research-project
cd my-research-project这个命令会为你生成标准的 pyproject.toml 以及一个基础的项目框架。与传统方式不同,你现在不需要手动去创建或激活虚拟环境。当你需要引入科学计算或机器学习相关的重型依赖时,直接添加即可:
uv add torch transformers执行这条命令后,uv 会在极短的时间内在后台自动为你下载合适的 Python 解释器(如果缺失的话)、创建 .venv 虚拟环境、解析依赖树,并通过全局缓存的硬链接完成安装。同时,它会将这两个包写入 pyproject.toml,并生成包含精确哈希值的 uv.lock 锁文件。
当你要执行代码时,直接使用:
uv run hello.pyuv 会自动接管上下文,使用当前项目的虚拟环境去运行你的脚本。如果后续你的合作者克隆了你的代码仓库,他们只需在目录中运行 uv sync,uv 就会严格按照 uv.lock 瞬间还原出与你分毫不差的底层环境。